
RESUMEN
Detección de Objetos en Tiempo Real con YOLO y Python
Guía completa para construir un sistema de detección de objetos en tiempo real utilizando la arquitectura YOLO y el lenguaje Python en 2026.
Keywords: YOLO, Visión Artificial, Tiempo Real
CONTEXTO
La Revolución de la Detección de Objetos en 2026
La detección de objetos, una rama fundamental de la visión artificial, ha evolucionado exponencialmente en la última década. En 2026, su aplicación se extiende desde la seguridad y vigilancia hasta la automatización industrial, los vehículos autónomos y el análisis de comportamiento en el comercio minorista. La capacidad de identificar y localizar objetos específicos dentro de imágenes o flujos de video en tiempo real no es solo una proeza técnica, sino una herramienta transformadora que impulsa la eficiencia y la seguridad en innumerables sectores.
«La detección de objetos en tiempo real es el pilar de la próxima generación de sistemas inteligentes, permitiendo a las máquinas ‘ver’ y ‘comprender’ su entorno con una precisión sin precedentes.»
— Kwonsejo, Análisis IT 2026
En este panorama, la familia de algoritmos YOLO (You Only Look Once) se ha consolidado como una de las soluciones más destacadas para la detección de objetos en tiempo real. Su equilibrio entre velocidad y precisión lo hace ideal para aplicaciones que requieren una respuesta inmediata. Combinado con la versatilidad y la robustez de Python, YOLO ofrece una plataforma poderosa para desarrolladores y entusiastas de la IA que buscan construir sistemas de visión artificial de vanguardia.
Este artículo de Kwonsejo tiene como objetivo proporcionar una guía práctica y exhaustiva para construir un sistema de detección de objetos en tiempo real utilizando YOLO y Python. Desde la preparación del entorno hasta el entrenamiento del modelo y su despliegue, desglosaremos cada paso con ejemplos de código y explicaciones claras, asegurando que incluso aquellos con experiencia limitada en deep learning puedan seguir el proceso y desarrollar sus propios proyectos innovadores para el año 2026.
PUNTO CLAVE
YOLO se ha convertido en el estándar de facto para la detección de objetos en tiempo real debido a su excepcional equilibrio entre velocidad y precisión, superando a muchos competidores en escenarios de baja latencia.
ÍNDICE
1 Fundamentos de YOLO y Visión Artificial
2 Preparación del Entorno de Desarrollo
3 Selección y Preparación del Conjunto de Datos
4 Entrenamiento de un Modelo YOLO Personalizado
5 Implementación de la Detección en Tiempo Real
6 Optimización y Despliegue
7 Casos de Uso y Perspectivas Futuras
FUNDAMENTOS
Fundamentos de YOLO y Visión Artificial
Antes de sumergirnos en la implementación, es crucial comprender qué es YOLO y cómo se inserta en el campo más amplio de la visión artificial. La visión artificial se ocupa de permitir que las computadoras «vean» y «procesen» imágenes de la misma manera que los humanos. Dentro de este campo, la detección de objetos es la tarea de identificar la presencia de objetos específicos en una imagen o video y dibujar un recuadro delimitador (bounding box) alrededor de cada uno, junto con su etiqueta de clase.
Históricamente, los métodos de detección de objetos se dividían en dos categorías principales: los detectores de dos etapas (como R-CNN, Fast R-CNN, Faster R-CNN) y los detectores de una etapa (como YOLO y SSD). Los detectores de dos etapas primero proponen regiones de interés y luego clasifican y refinan los cuadros delimitadores. Aunque son precisos, suelen ser más lentos. Los detectores de una etapa, por otro lado, predicen los cuadros delimitadores y las probabilidades de clase directamente en una sola pasada a través de la red, lo que los hace significativamente más rápidos.
La Arquitectura YOLO: Un Vistazo Detallado
YOLO fue introducido por primera vez en 2016 y desde entonces ha visto múltiples iteraciones (YOLOv1, YOLOv2, YOLOv3, YOLOv4, YOLOv5, YOLOR, YOLOX, y las más recientes YOLOv8 y YOLOv9 en 2026). Cada versión ha mejorado la precisión, la velocidad o ambas. La característica distintiva de YOLO es su enfoque «You Only Look Once», que procesa la imagen completa a través de una única red neuronal.
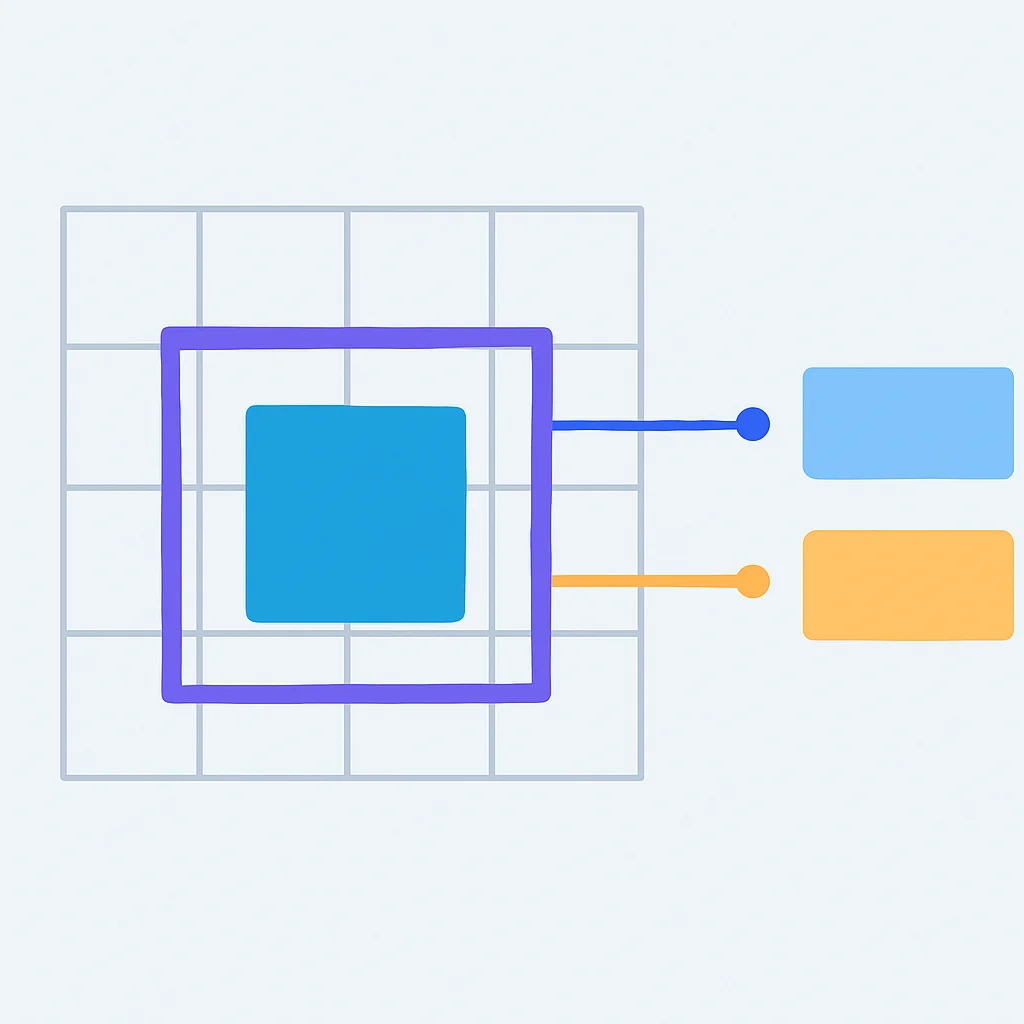
El principio fundamental de YOLO es dividir la imagen de entrada en una cuadrícula (por ejemplo, S x S). Cada celda de la cuadrícula es responsable de detectar objetos cuya parte central cae dentro de ella. Para cada celda, YOLO predice:
- Coordenadas del cuadro delimitador: (x, y, w, h), donde (x, y) son las coordenadas del centro del objeto, y (w, h) son el ancho y la altura del cuadro.
- Puntuación de confianza (confidence score): La probabilidad de que un objeto esté presente en el cuadro y la precisión del cuadro.
- Probabilidades de clase: La probabilidad condicional de que el objeto pertenezca a cada clase, dado que un objeto está presente.
Esta aproximación unificada permite que YOLO sea extremadamente rápido. A diferencia de otros sistemas que realizan múltiples pasadas o utilizan componentes separados para cada tarea, YOLO aprende a predecir todo directamente desde las características de la imagen, lo que lo convierte en una opción formidable para aplicaciones de tiempo real.
PUNTO CLAVE
La principal diferencia entre los detectores de una etapa (YOLO) y dos etapas (Faster R-CNN) radica en la velocidad; YOLO sacrifica una mínima precisión por una ganancia significativa en el rendimiento en tiempo real.
PREPARACIÓN
Preparación del Entorno de Desarrollo
Un entorno de desarrollo bien configurado es la base de cualquier proyecto de deep learning exitoso. Para nuestro sistema de detección de objetos con YOLO y Python, necesitaremos varias herramientas y bibliotecas. Es altamente recomendable usar un entorno virtual de Python para aislar las dependencias de este proyecto de otros en su sistema.
Instalación de Dependencias Clave
Comenzaremos creando un entorno virtual y activándolo. Esto nos asegura que todas las bibliotecas que instalemos sean específicas para este proyecto y no causen conflictos con otras configuraciones de Python.
EXPLICACIÓN DEL CÓDIGO
Estos comandos inicializan un entorno virtual llamado yolo_env y lo activan. Una vez activado, cualquier paquete de Python que instales solo estará disponible dentro de este entorno.
# Crear un entorno virtual
python3 -m venv yolo_env
# Activar el entorno virtual
source yolo_env/bin/activate # En Linux/macOS
# yolo_env\Scripts\activate # En Windows (CMD)
# yolo_env\Scripts\Activate.ps1 # En Windows (PowerShell)Una vez que el entorno virtual esté activo, procederemos a instalar las bibliotecas necesarias. Para YOLOv8/v9, la biblioteca ultralytics es la forma más sencilla de trabajar con los modelos más recientes. También necesitaremos OpenCV para el procesamiento de imágenes y video, y Pillow para manipulación de imágenes.
EXPLICACIÓN DEL CÓDIGO
Estos comandos instalan las bibliotecas esenciales. ultralytics proporciona la implementación de YOLO. opencv-python es fundamental para capturar video y dibujar sobre las imágenes. Pillow es una biblioteca de procesamiento de imágenes que a menudo es una dependencia para otras bibliotecas de visión artificial.
# Instalar ultralytics (para YOLOv8/v9)
pip install ultralytics
# Instalar OpenCV para Python
pip install opencv-python
# Instalar Pillow (a menudo una dependencia útil)
pip install PillowHerramientas Esenciales para su Proyecto YOLO
Python — Lenguaje de programación principal para el desarrollo.
Entornos Virtuales — Aislamiento de dependencias para evitar conflictos.
Ultralytics — Biblioteca oficial o de facto para las últimas versiones de YOLO (YOLOv8, YOLOv9).
OpenCV — Biblioteca fundamental para procesamiento de imágenes y video en tiempo real.
DATOS
Selección y Preparación del Conjunto de Datos
La calidad y cantidad de su conjunto de datos son los factores más críticos para el rendimiento de cualquier modelo de deep learning. Un modelo YOLO es tan bueno como los datos con los que se entrena. Para la detección de objetos, esto significa tener una colección diversa de imágenes con los objetos de interés correctamente anotados.
Existen varios conjuntos de datos públicos ampliamente utilizados, como COCO (Common Objects in Context) con 80 clases de objetos, o PASCAL VOC con 20 clases. Si su proyecto implica la detección de objetos comunes, puede optar por usar modelos YOLO pre-entrenados en estos conjuntos de datos. Sin embargo, para objetos específicos o escenarios únicos, necesitará entrenar un modelo personalizado con su propio conjunto de datos.
Anotación y Formato de Datos para YOLO
La anotación de datos es el proceso de dibujar cuadros delimitadores alrededor de los objetos en las imágenes y asignarles una etiqueta de clase. Para los modelos YOLO, el formato de anotación es específico: cada imagen debe tener un archivo de texto correspondiente con la misma base de nombre (por ejemplo, image.jpg y image.txt). Cada línea en el archivo .txt representa un objeto detectado y sigue el formato:
<class_id> <center_x> <center_y> <width> <height>
Donde class_id es un índice entero (0, 1, 2, …) de su lista de clases, y center_x, center_y, width, height son valores flotantes normalizados entre 0 y 1, relativos al ancho y alto de la imagen.
Herramientas como LabelImg o plataformas en la nube como Roboflow facilitan enormemente este proceso, permitiendo exportar las anotaciones directamente en el formato YOLO. Un conjunto de datos robusto debe incluir miles de imágenes, idealmente con variaciones en iluminación, ángulos, oclusiones y fondos para asegurar la generalización del modelo.
PUNTO CLAVE
La aumentación de datos (data augmentation) es crucial para mejorar la robustez de su modelo. Técnicas como rotaciones, volteos, cambios de brillo y escalado pueden generar nuevas variaciones de imágenes a partir de su conjunto de datos existente, reduciendo el sobreajuste y mejorando la generalización.
ENTRENAMIENTO
Entrenamiento de un Modelo YOLO Personalizado
Una vez que su conjunto de datos esté preparado en el formato YOLO, el siguiente paso es entrenar su modelo. Utilizaremos la biblioteca ultralytics, que simplifica enormemente el proceso de entrenamiento de modelos YOLOv8 y YOLOv9. El entrenamiento generalmente requiere una GPU para ser eficiente, aunque es posible ejecutarlo en CPU para conjuntos de datos pequeños o con fines de prueba (pero será significativamente más lento).
Configuración del Archivo YAML
Para que el modelo sepa dónde encontrar sus datos y qué clases detectar, necesita un archivo de configuración YAML. Este archivo especifica las rutas a las imágenes de entrenamiento y validación, así como la lista de nombres de clases.
EXPLICACIÓN DEL CÓDIGO
Este archivo data.yaml define la estructura de su conjunto de datos. path es la ruta base a su conjunto de datos. train y val especifican las subcarpetas de imágenes para entrenamiento y validación. nc es el número de clases, y names es la lista de los nombres de sus clases en orden.
# data.yaml
path: /ruta/a/su/dataset # Ruta principal a su conjunto de datos
train: images/train # Ruta a las imágenes de entrenamiento
val: images/val # Ruta a las imágenes de validación
test: images/test # (Opcional) Ruta a las imágenes de prueba
# Clases
nc: 3 # Número de clases
names: ['persona', 'coche', 'bicicleta'] # Nombres de las clasesEjecución del Entrenamiento
Con el archivo data.yaml listo, puede iniciar el entrenamiento utilizando el comando yolo de la biblioteca ultralytics. Es posible elegir entre diferentes tamaños de modelo (nano, small, medium, large, xlarge) que ofrecen diferentes compromisos entre velocidad y precisión.
EXPLICACIÓN DEL CÓDIGO
Este comando inicia el entrenamiento de un modelo YOLOv8 m (medium). data apunta a su archivo de configuración YAML. epochs define el número de pasadas completas sobre el conjunto de datos de entrenamiento. imgsz establece la resolución de la imagen de entrada, y batch el tamaño del lote.
# Entrenar un modelo YOLOv8m
yolo train model=yolov8m.pt data=data.yaml epochs=100 imgsz=640 batch=16Durante el entrenamiento, el modelo ajustará sus pesos para minimizar la pérdida de detección y clasificación. Es crucial monitorear métricas como la pérdida de entrenamiento y validación, mAP (mean Average Precision) en diferentes umbrales (mAP50, mAP50-95). Un buen entrenamiento mostrará una disminución constante en la pérdida de validación y un aumento en el mAP de validación.
«La clave para un modelo de detección de objetos robusto reside no solo en la cantidad de datos, sino en la diversidad y la precisión de sus anotaciones, junto con una cuidadosa sintonización de hiperparámetros.»
— Equipo de IA de Kwonsejo
Ventajas del Entrenamiento Personalizado
✓ Precisión Específica: Optimizado para sus clases y escenarios únicos.
✓ Rendimiento Mejorado: Supera a los modelos pre-entrenados en dominios especializados.
✓ Control Total: Adaptación completa de hiperparámetros y arquitectura.
Desventajas
✗ Recursos Computacionales: Requiere GPUs potentes y tiempo considerable.
✗ Dependencia de Datos: Exige un conjunto de datos grande y de alta calidad.
✗ Curva de Aprendizaje: Implica conocimientos de deep learning y herramientas asociadas.
IMPLEMENTACIÓN
Implementación de la Detección en Tiempo Real
Una vez que haya entrenado su modelo YOLO (o haya descargado uno pre-entrenado), el paso final es integrarlo en una aplicación de detección en tiempo real. Esto generalmente implica capturar un flujo de video (desde una cámara web, un archivo de video o una transmisión en vivo), procesar cada fotograma con el modelo YOLO y luego visualizar los resultados.
Carga del Modelo y Preprocesamiento
El primer paso en su script de Python será cargar el modelo entrenado y configurar la captura de video. Utilizaremos OpenCV (cv2) para la interacción con la cámara.
EXPLICACIÓN DEL CÓDIGO
Este fragmento de código importa las bibliotecas necesarias. Carga el modelo YOLO entrenado (por ejemplo, best.pt si lo entrenó usted mismo, o yolov8n.pt para un modelo nano pre-entrenado). Luego, inicializa la captura de video desde la cámara web predeterminada (índice 0).
import cv2
from ultralytics import YOLO
# Cargar el modelo YOLO. Puede ser un modelo pre-entrenado o el suyo.
# model = YOLO('yolov8n.pt') # Modelo nano pre-entrenado
model = YOLO('runs/detect/train/weights/best.pt') # Su modelo entrenado
# Inicializar la captura de video desde la cámara web (0 para la cámara predeterminada)
cap = cv2.VideoCapture(0)
# Verificar si la cámara se abrió correctamente
if not cap.isOpened():
print("Error: No se pudo abrir la cámara.")
exit()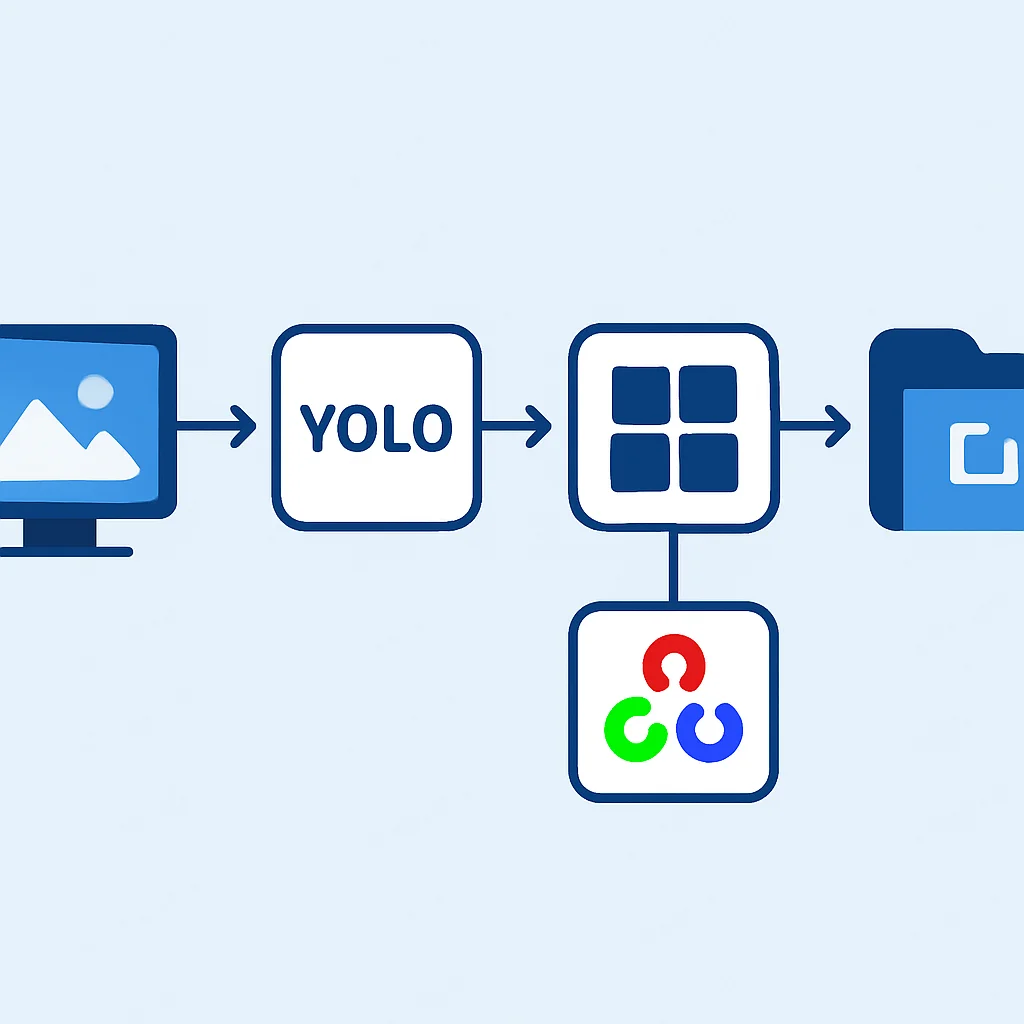
Bucle de Detección y Visualización
El corazón de la aplicación en tiempo real es un bucle que lee fotogramas de la cámara, realiza la detección y muestra los resultados. Para cada fotograma, el modelo YOLO generará predicciones que incluyen las coordenadas de los cuadros delimitadores, las puntuaciones de confianza y las etiquetas de clase. Luego, usaremos OpenCV para dibujar estos resultados en el fotograma y mostrarlo.
EXPLICACIÓN DEL CÓDIGO
Este bucle while True lee continuamente fotogramas de la cámara. La línea results = model(frame, stream=True) ejecuta la inferencia YOLO. annotated_frame = r.plot() es una función conveniente de ultralytics que dibuja automáticamente los cuadros delimitadores y etiquetas. Finalmente, cv2.imshow muestra el fotograma anotado.
while True:
ret, frame = cap.read()
if not ret:
print("Error: No se pudo leer el fotograma. Saliendo...")
break
# Realizar detección de objetos en el fotograma
# stream=True para procesar el video de manera más eficiente
results = model(frame, stream=True)
# Iterar sobre los resultados y dibujar los cuadros delimitadores
for r in results:
# La función plot() de ultralytics dibuja los bounding boxes y etiquetas
annotated_frame = r.plot()
# También podemos acceder a los datos raw si queremos personalizar
# boxes = r.boxes.xyxy.cpu().numpy() # Formato [x1, y1, x2, y2]
# confs = r.boxes.conf.cpu().numpy()
# class_ids = r.boxes.cls.cpu().numpy()
# names = r.names # Diccionario de {id: nombre_clase}
# Ejemplo de dibujo manual (si no usas r.plot()):
# for box, conf, class_id in zip(boxes, confs, class_ids):
# x1, y1, x2, y2 = map(int, box)
# label = f"{names[int(class_id)]}: {conf:.2f}"
# cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 255, 0), 2)
# cv2.putText(frame, label, (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
# annotated_frame = frame # Si dibujas manualmente
# Mostrar el fotograma anotado
cv2.imshow('Deteccion de Objetos en Tiempo Real (Kwonsejo)', annotated_frame)
# Salir si se presiona la tecla 'q'
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Liberar la cámara y destruir todas las ventanas
cap.release()
cv2.destroyAllWindows()PUNTO CLAVE
Para optimizar el rendimiento en tiempo real, asegúrese de que su entorno esté utilizando CUDA si tiene una GPU compatible. Esto acelerará significativamente la inferencia del modelo, permitiendo tasas de fotogramas (FPS) más altas.
OPTIMIZACIÓN
Optimización y Despliegue
Lograr la detección de objetos en tiempo real no siempre es solo cuestión de usar YOLO. En muchos escenarios, especialmente en dispositivos de borde o con recursos limitados, es necesario optimizar el modelo para maximizar el rendimiento. Esto puede implicar reducir el tamaño del modelo, utilizar hardware especializado o ajustar los parámetros de inferencia.
Cuantificación y Poda (Pruning)
Dos técnicas comunes para reducir el tamaño y acelerar la inferencia de los modelos de deep learning son la cuantificación y la poda:
- Cuantificación: Reduce la precisión numérica de los pesos y activaciones del modelo (por ejemplo, de flotantes de 32 bits a enteros de 8 bits). Esto disminuye el tamaño del modelo y permite cálculos más rápidos, a menudo con una pérdida mínima en la precisión. Herramientas como
TensorRT(NVIDIA) oOpenVINO(Intel) pueden aplicar cuantificación. - Poda (Pruning): Elimina conexiones o neuronas menos importantes de la red neuronal. Esto reduce la complejidad del modelo y el número de operaciones, lo que puede resultar en una inferencia más rápida. La poda puede ser estructurada o no estructurada.
Hardware Acelerado
El hardware juega un papel crucial en el rendimiento en tiempo real:
- GPUs (Unidades de Procesamiento Gráfico): Son el estándar de oro para el deep learning, ofreciendo paralelización masiva. Las GPUs NVIDIA con
CUDAson la elección más común. - TPUs (Unidades de Procesamiento Tensorial): Desarrolladas por Google, están optimizadas para cargas de trabajo de deep learning y pueden ofrecer un rendimiento excelente para ciertos modelos.
- Dispositivos de Borde (Edge Devices): Para aplicaciones en el borde de la red, plataformas como NVIDIA Jetson (Nano, Xavier NX), Google Coral Edge TPU o Raspberry Pi con aceleradores de IA son opciones populares. Estos dispositivos ofrecen una combinación de potencia computacional y eficiencia energética para ejecutar modelos de IA localmente.
PROBLEMA 01
Bajo Rendimiento (Bajos FPS) en Detección en Tiempo Real
Su sistema de detección de objetos con YOLO funciona, pero la tasa de fotogramas (FPS) es demasiado baja para considerarse «tiempo real», especialmente en hardware modesto.
SOLUCIÓN — Optimización del Modelo y del Entorno
# 1. Usar un modelo YOLO más pequeño (e.g., nano o small)
# model = YOLO('yolov8n.pt')
# 2. Reducir la resolución de la imagen de entrada (imgsz)
# model(frame, imgsz=320, stream=True) # Reducir a 320px
# 3. Exportar el modelo a un formato optimizado (ej. ONNX, TensorRT)
# model.export(format='onnx', opset=12) # Exportar a ONNX
# model.export(format='engine', device=0) # Exportar a TensorRT (requiere GPU NVIDIA)
# 4. Asegurarse de que CUDA esté activado (si hay GPU)
# import torch
# print(torch.cuda.is_available()) # Debe ser True si CUDA funciona
# 5. Optimizar el código Python (ej. evitar operaciones costosas dentro del bucle)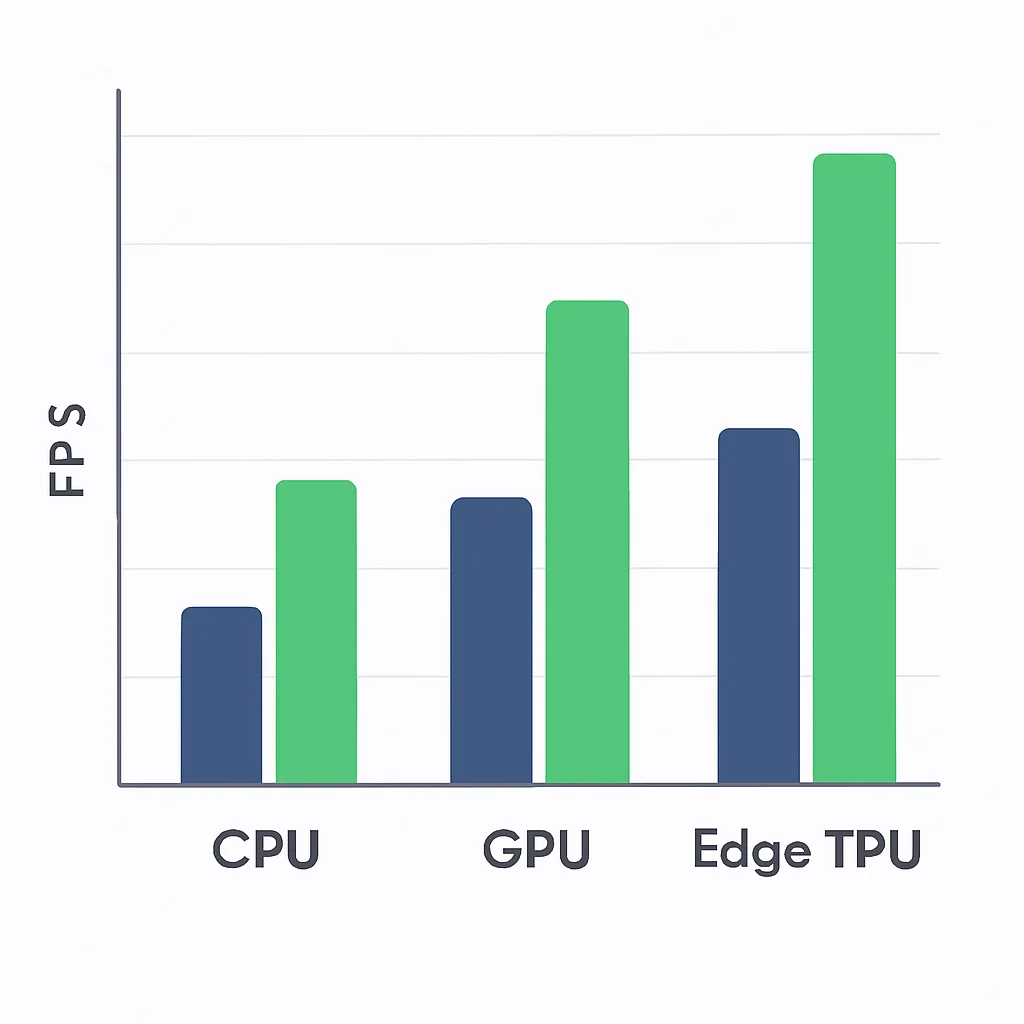
El despliegue de su sistema puede variar desde una aplicación de escritorio local hasta un servicio en la nube o un dispositivo de borde. Para la mayoría de las aplicaciones de tiempo real, la ejecución local en una GPU o un dispositivo de borde es preferible para minimizar la latencia. La elección del hardware y las técnicas de optimización dependerán de los requisitos específicos de su proyecto en términos de velocidad, precisión y consumo de energía.
APLICACIONES
Casos de Uso y Perspectivas Futuras
La detección de objetos en tiempo real con YOLO tiene un impacto profundo en una multitud de industrias. Su capacidad para procesar información visual de manera instantánea abre puertas a soluciones innovadoras y eficientes en 2026 y más allá.
Automatización Industrial y Control de Calidad
Inspección de defectos en líneas de producción, conteo de componentes y robots colaborativos.
Seguridad y Vigilancia Inteligente
Detección de intrusos, reconocimiento de actividades sospechosas, monitoreo de multitudes y seguridad perimetral.
Vehículos Autónomos y Sistemas de Asistencia al Conductor (ADAS)
Detección de peatones, otros vehículos, señales de tráfico y obstáculos para una conducción segura.
Retail y Análisis de Comportamiento
Seguimiento de inventario, análisis de flujo de clientes, detección de robos y optimización de la disposición de productos.
Agricultura Inteligente
Detección de plagas, monitoreo de crecimiento de cultivos, conteo de animales y automatización de cosechas.
Mirando hacia el futuro, la evolución de YOLO y otras arquitecturas de detección de objetos continuará a un ritmo acelerado. En 2026, estamos viendo avances en modelos más ligeros y eficientes para dispositivos de borde, así como la integración con modelos basados en transformadores que prometen una mayor precisión en escenarios complejos. La capacidad de detectar objetos en 3D y la fusión de datos de múltiples sensores (cámaras, LiDAR, radar) también serán áreas clave de desarrollo.
PUNTO CLAVE
La ética y la privacidad son consideraciones fundamentales en el despliegue de sistemas de detección de objetos. Es vital asegurar el uso responsable de estas tecnologías, especialmente en aplicaciones de vigilancia o que involucren datos personales.
Preguntas Frecuentes (FAQ)
Q. ¿Por qué debería usar YOLO en lugar de otros detectores de objetos?
YOLO se destaca por su excelente equilibrio entre velocidad y precisión, lo que lo hace ideal para aplicaciones en tiempo real. Su arquitectura de una sola etapa procesa imágenes más rápido que los detectores de dos etapas, manteniendo un alto nivel de exactitud.
Q. ¿Necesito una GPU para entrenar un modelo YOLO?
Aunque es posible entrenar en una CPU, una GPU es altamente recomendable y prácticamente esencial para conjuntos de datos grandes o modelos complejos. Acelera significativamente el proceso de entrenamiento, reduciendo el tiempo de días a horas o minutos.
Q. ¿Cómo puedo mejorar la precisión de mi modelo YOLO personalizado?
Para mejorar la precisión, asegúrese de tener un conjunto de datos grande y diverso con anotaciones de alta calidad. Experimente con técnicas de aumentación de datos, ajuste de hiperparámetros (como el número de épocas o el tamaño del lote) y considere usar un modelo YOLO más grande si los recursos lo permiten.
Q. ¿Es posible ejecutar YOLO en un dispositivo de borde como Raspberry Pi?
Sí, es posible. Sin embargo, para obtener un rendimiento aceptable en tiempo real, necesitará optimizar el modelo (cuantificación, poda) y posiblemente utilizar un acelerador de IA como Google Coral Edge TPU o NVIDIA Jetson, ya que la CPU de Raspberry Pi por sí sola no es suficiente.
¡Gracias por leer!
Esperamos que esta guía detallada le haya proporcionado los conocimientos y las herramientas necesarias para construir su propio sistema de detección de objetos en tiempo real con YOLO y Python. El campo de la visión artificial está en constante evolución, y las posibilidades son ilimitadas.
¿Preguntas? ¡Déjalas en los comentarios! Y no olvides visitar Kwonsejo.com para más análisis y guías de IT.