

RESUMEN
Guía completa para construir un pipeline MLOps con Kubeflow en 2026
Optimiza el ciclo de vida de tus modelos de Machine Learning con Kubeflow.
Keywords: MLOps, Kubeflow, Kubernetes
ÍNDICE
1. La Importancia de MLOps en 2026 y el Rol de Kubeflow
2. Componentes Esenciales de Kubeflow para MLOps
3. Configuración de Kubeflow en un Cluster de Kubernetes
4. Construyendo un Pipeline MLOps con Kubeflow Pipelines
5. Despliegue de Modelos con KFServing
6. Monitoreo y Gestión de Modelos en Producción
7. Prácticas Avanzadas y CI/CD en MLOps con Kubeflow
8. Desafíos Comunes y Mejores Prácticas
9. Kubeflow vs. Otros Frameworks MLOps: Un Análisis Comparativo
10. Preguntas Frecuentes (FAQ)
INTRODUCCIÓN
1. La Importancia de MLOps en 2026 y el Rol de Kubeflow
En el dinámico panorama tecnológico de 2026, la Inteligencia Artificial (IA) y el Machine Learning (ML) han trascendido de ser meras herramientas experimentales a convertirse en componentes críticos para la innovación empresarial. Sin embargo, la creación de modelos de ML de alto rendimiento es solo una parte de la ecuación. El verdadero desafío reside en cómo llevar estos modelos desde la fase de investigación y desarrollo hasta la producción de manera eficiente, escalable y sostenible. Aquí es donde MLOps (Machine Learning Operations) entra en juego.
MLOps es una disciplina que combina las mejores prácticas de DevOps con las particularidades del desarrollo de Machine Learning. Su objetivo es automatizar y estandarizar el ciclo de vida completo de un modelo de ML, desde la adquisición de datos y el entrenamiento, hasta el despliegue, monitoreo y reentrenamiento. Sin una estrategia MLOps robusta, las organizaciones se enfrentan a problemas como la falta de reproducibilidad, el ‘drift’ del modelo, el despliegue lento y la dificultad para escalar, lo que puede resultar en costos operativos elevados y una pérdida de ventaja competitiva.
Dentro de este contexto, Kubeflow emerge como una solución integral y de código abierto que busca democratizar el MLOps, permitiendo a los equipos de ML operar en entornos de Kubernetes. Al aprovechar la escalabilidad, la portabilidad y la gestión de recursos que ofrece Kubernetes, Kubeflow proporciona un conjunto de herramientas para cada etapa del ciclo de vida del ML, desde la experimentación hasta el despliegue en producción. Esto lo convierte en una opción atractiva para organizaciones que ya utilizan Kubernetes o que buscan una plataforma MLOps flexible y extensible.
FUNDAMENTOS
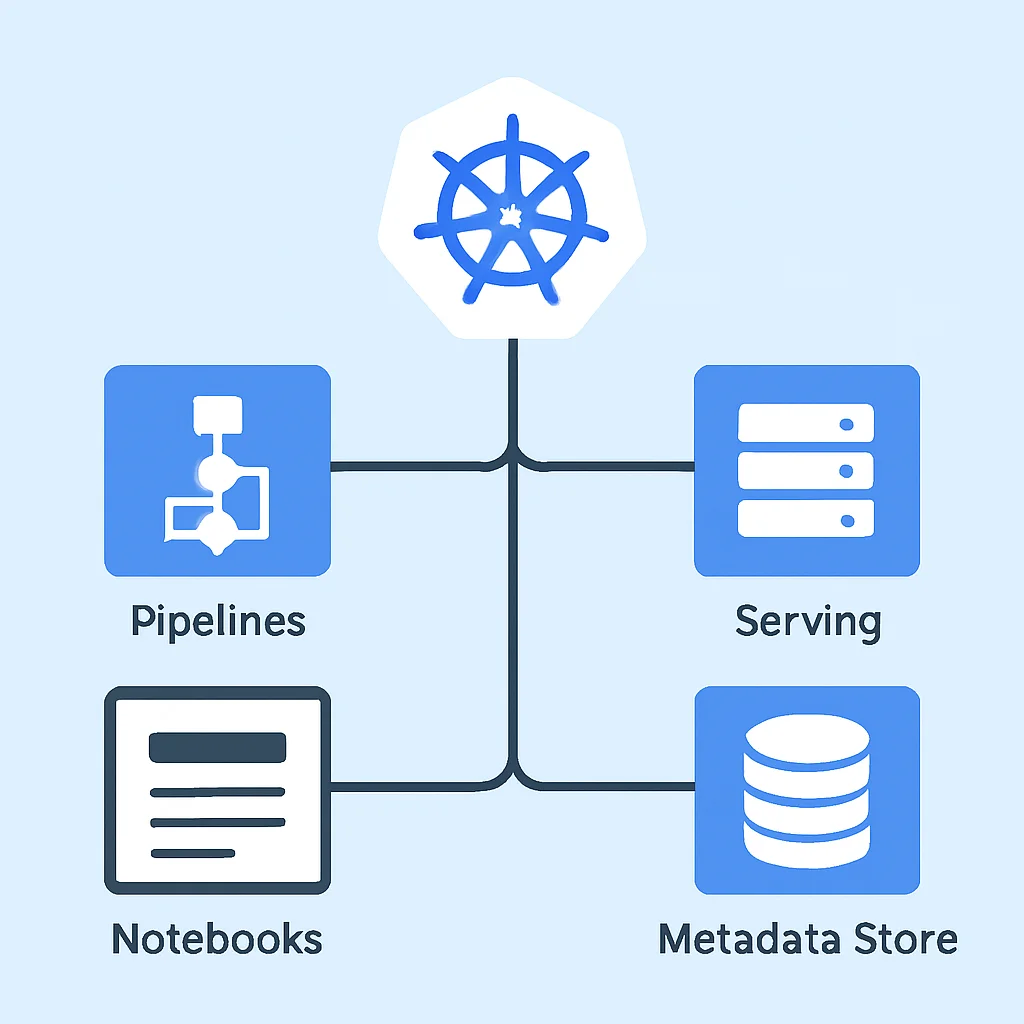
2. Componentes Esenciales de Kubeflow para MLOps
Kubeflow no es una herramienta monolítica, sino una colección de componentes de código abierto diseñados para trabajar juntos en Kubernetes. Cada componente aborda una fase específica del ciclo de vida de MLOps, ofreciendo flexibilidad para usar solo lo que se necesita o integrar herramientas externas.
Componentes Clave de Kubeflow
Kubeflow Pipelines (KFP) — Un motor para construir y desplegar flujos de trabajo de ML reproducibles y escalables. Permite orquestar tareas de ML como preparación de datos, entrenamiento, evaluación y despliegue.
KFServing (KServe) — Proporciona un servidor de inferencia de alto rendimiento y escalable para desplegar modelos de ML en Kubernetes. Soporta características avanzadas como autoescalado, canary rollouts y detección de modelos.
Katib — Un sistema de optimización de hiperparámetros y selección de arquitectura neuronal (NAS) para Machine Learning. Automatiza la búsqueda de los mejores parámetros para sus modelos.
Jupyter Notebooks — Integración directa para entornos de desarrollo interactivos, permitiendo a los científicos de datos experimentar y desarrollar modelos directamente dentro del cluster de Kubernetes.
Metadata Store — Almacena información sobre los artefactos, ejecuciones y modelos de ML, facilitando la reproducibilidad y el rastreo de experimentos.
Volcano — Un sistema de programación por lotes para Kubernetes, optimizado para cargas de trabajo de ML de alto rendimiento, como entrenamiento distribuido.
Estos componentes trabajan en conjunto para formar una plataforma integral de MLOps. Por ejemplo, los científicos de datos pueden desarrollar sus modelos en Jupyter Notebooks, orquestar el entrenamiento y la evaluación con Kubeflow Pipelines, optimizar los hiperparámetros con Katib, y finalmente desplegar sus modelos con KFServing. La clave de Kubeflow es su flexibilidad y su capacidad para integrarse con otras herramientas del ecosistema de Kubernetes.
La elección de Kubeflow para su estrategia MLOps en 2026 ofrece varias ventajas, incluyendo:
Ventajas de Kubeflow
✓ Portabilidad: Ejecuta tus cargas de trabajo de ML en cualquier cluster de Kubernetes, ya sea on-premise o en la nube.
✓ Escalabilidad: Aprovecha las capacidades de escalado horizontal de Kubernetes para manejar grandes volúmenes de datos y modelos.
✓ Open Source: Flexibilidad para personalizar y extender la plataforma según las necesidades específicas de su organización.
✓ Ecosistema Maduro: Integración con herramientas populares de ML (TensorFlow, PyTorch, Scikit-learn) y de Kubernetes.
IMPLEMENTACIÓN
3. Configuración de Kubeflow en un Cluster de Kubernetes
Antes de sumergirnos en la construcción de pipelines, es fundamental tener un entorno Kubeflow funcional. La instalación de Kubeflow requiere un cluster de Kubernetes existente. Puede ser un cluster local (minikube, kind) para desarrollo o un cluster en la nube (GKE, EKS, AKS) para producción. Para esta guía, asumiremos que ya tiene un cluster de Kubernetes configurado y kubectl configurado para interactuar con él.
Requisitos Previos
Asegúrese de que su cluster de Kubernetes cumple con los siguientes requisitos mínimos:
☑ Kubernetes versión 1.22 o superior.
☑ Al menos 4 vCPUs y 16 GB de RAM disponibles (recomendado para una instalación básica).
☑ Un controlador de Ingress (como NGINX Ingress Controller) instalado y configurado.
☑ Acceso a Internet para descargar imágenes de Docker.
Pasos de Instalación de Kubeflow
Utilizaremos kfctl, la herramienta de línea de comandos de Kubeflow, para la instalación. Siga estos pasos:
1
Descargar kfctl
Descargue la última versión de kfctl para su sistema operativo. Para Linux/macOS, puede usar curl y moverlo a su PATH.
Este comando descarga la versión 1.7.0 de kfctl, la hace ejecutable y la mueve a un directorio accesible en su PATH.
# Versión de Kubeflow que usaremos para 2026, por ejemplo, v1.7.0 o superior
export KF_VERSION="1.7.0"
export KF_PLATFORM="kfctl_k8s_istio" # Para instalación en Kubernetes con Istio
curl --silent --location "https://github.com/kubeflow/kubeflow/releases/download/v${KF_VERSION}/kfctl_v${KF_VERSION}_linux_amd64.tar.gz" | tar -xz
sudo mv kfctl /usr/local/bin/
sudo chmod +x /usr/local/bin/kfctl
2
Crear un directorio de configuración y descargar los archivos de manifiesto
Este paso inicializa el directorio de configuración de Kubeflow donde se almacenarán los manifiestos YAML necesarios para el despliegue.
3
Desplegar Kubeflow
Este comando aplica los manifiestos descargados a su cluster de Kubernetes, iniciando el despliegue de todos los componentes de Kubeflow.
Una vez completada la instalación, puede acceder al dashboard de Kubeflow a través del Ingress configurado en su cluster. Generalmente, esto implica encontrar la IP externa del servicio istio-ingressgateway en el namespace istio-system y configurarla con un DNS o acceder directamente.
PUNTO CLAVE
La instalación de Kubeflow puede consumir una cantidad significativa de recursos. Asegúrese de que su cluster de Kubernetes tenga suficiente capacidad (al menos 8 vCPUs y 32 GB de RAM para un entorno de desarrollo robusto) para evitar problemas de rendimiento.
PIPELINES MLOPS
4. Construyendo un Pipeline MLOps con Kubeflow Pipelines
El corazón de MLOps en Kubeflow es Kubeflow Pipelines (KFP), que permite definir y ejecutar flujos de trabajo de ML reproducibles. Un pipeline de KFP se compone de una serie de «componentes», donde cada componente es una función Python que encapsula una tarea específica (ej. preprocesamiento, entrenamiento). Estos componentes se ejecutan como contenedores Docker en Kubernetes.
Definiendo Componentes de Pipeline
Para ilustrar, crearemos un pipeline sencillo para entrenar un modelo de clasificación de iris. El pipeline tendrá tres componentes: preparación de datos, entrenamiento del modelo y evaluación del modelo.
Primero, definamos los componentes individuales usando el SDK de Kubeflow Pipelines.
EXPLICACIÓN DEL CÓDIGO
Estos son los componentes de nuestro pipeline. Cada función decorada con @kfp.v2.component se convierte en un contenedor ejecutable. Los argumentos de entrada y salida definen cómo se comunican los componentes. Se utiliza una imagen base de Python con scikit-learn y pandas preinstalados.
import kfp
from kfp.v2 import dsl
from kfp.v2.dsl import (
component,
Input,
Output,
Artifact,
Dataset,
Model,
Metrics
)
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
import json
BASE_IMAGE = 'python:3.9-slim-buster'
SKLEARN_IMAGE = 'python:3.9-slim-buster' # Asumimos sklearn ya instalado o lo instalamos en el contenedor
# Componente 1: Preparación de Datos
@component(base_image=SKLEARN_IMAGE, packages_to_install=['scikit-learn', 'pandas'])
def prepare_data(
test_size: float,
random_state: int,
output_dataset_train: Output[Dataset],
output_dataset_test: Output[Dataset]
):
from sklearn.datasets import load_iris
iris = load_iris()
X = pd.DataFrame(iris.data, columns=iris.feature_names)
y = pd.Series(iris.target)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=test_size, random_state=random_state
)
pd.concat([X_train, y_train.rename('target')], axis=1).to_csv(output_dataset_train.path, index=False)
pd.concat([X_test, y_test.rename('target')], axis=1).to_csv(output_dataset_test.path, index=False)
print(f"Datos preparados. Train samples: {len(X_train)}, Test samples: {len(X_test)}")
# Componente 2: Entrenamiento del Modelo
@component(base_image=SKLEARN_IMAGE, packages_to_install=['scikit-learn', 'pandas'])
def train_model(
input_dataset_train: Input[Dataset],
n_estimators: int,
random_state: int,
output_model: Output[Model]
):
df_train = pd.read_csv(input_dataset_train.path)
X_train = df_train.drop('target', axis=1)
y_train = df_train['target']
model = RandomForestClassifier(n_estimators=n_estimators, random_state=random_state)
model.fit(X_train, y_train)
import joblib
joblib.dump(model, output_model.path + '.joblib')
print("Modelo entrenado y guardado.")
# Componente 3: Evaluación del Modelo
@component(base_image=SKLEARN_IMAGE, packages_to_install=['scikit-learn', 'pandas'])
def evaluate_model(
input_model: Input[Model],
input_dataset_test: Input[Dataset],
metrics: Output[Metrics]
):
df_test = pd.read_csv(input_dataset_test.path)
X_test = df_test.drop('target', axis=1)
y_test = df_test['target']
import joblib
model = joblib.load(input_model.path + '.joblib')
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred, output_dict=True)
metrics.log_metric("accuracy", accuracy)
metrics.log_metric("classification_report", json.dumps(report))
print(f"Precisión del modelo: {accuracy}")
print("Reporte de clasificación:")
print(json.dumps(report, indent=2))
Estos componentes Python serán compilados por KFP en contenedores Docker y ejecutados en su cluster de Kubernetes.
Definiendo el Pipeline
Ahora, combinamos estos componentes en un pipeline completo utilizando el decorador @dsl.pipeline.
EXPLICACIÓN DEL CÓDIGO
Esta función define el flujo de trabajo. Cada llamada a un componente (prepare_data_task, train_model_task, etc.) representa un paso en el pipeline. Las dependencias se gestionan automáticamente a través de las entradas y salidas de los componentes.
@dsl.pipeline(
name='Iris Classifier Pipeline',
description='Un pipeline MLOps para entrenar y evaluar un clasificador de Iris.',
pipeline_root='gs://your-gcs-bucket/kubeflow-pipelines' # Cambiar por su bucket de GCS o S3
)
def iris_classifier_pipeline(
test_size: float = 0.2,
random_state: int = 42,
n_estimators: int = 100
):
prepare_data_task = prepare_data(
test_size=test_size,
random_state=random_state
)
train_model_task = train_model(
input_dataset_train=prepare_data_task.outputs["output_dataset_train"],
n_estimators=n_estimators,
random_state=random_state
)
evaluate_model_task = evaluate_model(
input_model=train_model_task.outputs["output_model"],
input_dataset_test=prepare_data_task.outputs["output_dataset_test"]
)
Compilando y Ejecutando el Pipeline
Una vez definido, el pipeline debe compilarse en un archivo YAML que Kubeflow Pipelines pueda entender, y luego subirse al servicio de KFP.
EXPLICACIÓN DEL CÓDIGO
Estos comandos compilan el pipeline Python a un archivo YAML y luego utilizan el cliente de KFP para subir y ejecutar el pipeline en el servidor de Kubeflow Pipelines.
# Compilar el pipeline
kfp.v2.compiler.Compiler().compile(
pipeline_func=iris_classifier_pipeline,
package_path='iris_pipeline.yaml'
)
# Subir y ejecutar el pipeline (ejecutar desde un entorno con acceso al cluster KFP)
# Asegúrese de tener el cliente KFP configurado para su endpoint
from kfp import Client
client = Client(host='http://localhost:8080') # Reemplazar con la URL de su dashboard KFP
# Crear un experimento
experiment = client.create_experiment(name="Iris Classification Experiment")
# Ejecutar el pipeline
run = client.create_run_from_pipeline_func(
iris_classifier_pipeline,
arguments={
'test_size': 0.3,
'n_estimators': 150
},
experiment_id=experiment.id,
mode=kfp.dsl.PipelineExecutionMode.V2_COMPATIBLE # Para Kubeflow Pipelines v2
)
print(f"Pipeline ejecutado: {run.url}")
Al ejecutar este código, el pipeline se desplegará en Kubeflow Pipelines. Podrá monitorear su progreso, ver los logs de cada componente y examinar los artefactos generados (como el modelo entrenado y las métricas de evaluación) directamente desde la interfaz de usuario de Kubeflow.
PUNTO CLAVE
La versión 2 de Kubeflow Pipelines (KFP v2) introdujo un nuevo SDK que mejora la portabilidad y la integración con entornos de ejecución DAG. Asegúrese de usar el SDK kfp.v2 para los pipelines modernos.
DESPLIEGUE
5. Despliegue de Modelos con KFServing
Una vez que nuestro modelo ha sido entrenado y evaluado satisfactoriamente, el siguiente paso crítico es desplegarlo para que pueda servir predicciones en producción. KFServing (ahora KServe) es el componente de Kubeflow diseñado específicamente para este propósito, ofreciendo una solución de inferencia de modelos escalable y de alto rendimiento en Kubernetes.
KFServing simplifica el despliegue al abstraer la complejidad de la infraestructura subyacente. Permite desplegar modelos de diferentes frameworks (TensorFlow, PyTorch, Scikit-learn, XGBoost, ONNX) con unos pocos comandos YAML, y ofrece características como autoescalado a cero, revisiones de modelos y despliegues canary/blue-green.
Despliegue de un Modelo Scikit-learn con KFServing
Para desplegar el modelo de Random Forest entrenado en el pipeline anterior, primero debemos asegurarnos de que el modelo esté almacenado en una ubicación accesible por KFServing, como un bucket de S3 o Google Cloud Storage (GCS). Asumiremos que el archivo model.joblib se subió a gs://your-model-bucket/iris-classifier/model.joblib.
EXPLICACIÓN DEL CÓDIGO
Este manifiesto YAML define un InferenceService para nuestro modelo de Iris. Especifica el nombre, el framework (scikit-learn), y la ubicación del modelo almacenado. KFServing automáticamente crea los recursos de Kubernetes necesarios para servir el modelo.
apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: iris-classifier
namespace: kubeflow # O el namespace donde Kubeflow está instalado
spec:
predictor:
sklearn:
storageUri: gs://your-model-bucket/iris-classifier/ # Asegúrate de que este bucket sea accesible
# resources:
# limits:
# cpu: "1"
# memory: "2Gi"
# requests:
# cpu: "0.5"
# memory: "1Gi"
minReplicas: 1 # Asegura que al menos una réplica esté siempre activa
maxReplicas: 3 # Permite autoescalado hasta 3 réplicas
Guarde este contenido como iris-inference-service.yaml y aplíquelo a su cluster:
EXPLICACIÓN DEL CÓDIGO
Este comando utiliza kubectl para aplicar el manifiesto de InferenceService a su cluster de Kubernetes, creando así el endpoint de inferencia.
kubectl apply -f iris-inference-service.yaml
KFServing creará automáticamente un Pod de KNative Service que cargará su modelo y lo expondrá a través de un endpoint HTTP. Puede verificar el estado del servicio y obtener su URL:
EXPLICACIÓN DEL CÓDIGO
Estos comandos le permiten monitorear el progreso del despliegue y obtener la URL de inferencia una vez que el servicio esté listo. La URL es el punto de entrada para enviar solicitudes de predicción a su modelo.
kubectl get inferenceservice -n kubeflow iris-classifier
# Esperar hasta que el estado sea "Ready"
# Obtener la URL de inferencia
kubectl get inferenceservice -n kubeflow iris-classifier -o jsonpath='{.status.address.url}'
Una vez que tenga la URL, puede enviar solicitudes de predicción al modelo. Por ejemplo, utilizando curl:
EXPLICACIÓN DEL CÓDIGO
Este comando curl envía datos de ejemplo al endpoint de inferencia del modelo. El formato de la carga útil JSON es el estándar de KFServing para modelos scikit-learn.
SERVICE_HOSTNAME=$(kubectl get inferenceservice -n kubeflow iris-classifier -o jsonpath='{.status.address.url}' | cut -d'/' -f3)
MODEL_NAME="iris-classifier"
curl -v -H "Host: ${SERVICE_HOSTNAME}" -H "Content-Type: application/json" \
"http://${SERVICE_HOSTNAME}/v1/models/${MODEL_NAME}:predict" \
-d '{ "instances": [ [6.7, 3.0, 5.2, 2.3], [5.0, 3.5, 1.3, 0.3] ] }'
La respuesta contendrá las predicciones de su modelo, como {"predictions": [2, 0]}, indicando las clases predichas para los datos de entrada.
PUNTO CLAVE
KFServing se integra con Istio para la gestión del tráfico y la seguridad, y con KNative para el autoescalado, incluso a cero, lo que reduce significativamente los costos cuando el modelo no está en uso.
MONITOREO Y GESTIÓN
6. Monitoreo y Gestión de Modelos en Producción
El despliegue de un modelo es solo el principio. Para asegurar que los modelos de ML sigan siendo efectivos a lo largo del tiempo, es crucial implementar un monitoreo continuo y mecanismos de gestión robustos. Esto incluye la detección de drift de datos y modelos, el seguimiento del rendimiento y la capacidad de reentrenar y actualizar modelos de manera eficiente.
Monitoreo de Rendimiento y Drift
Kubeflow no incluye un componente de monitoreo de modelos nativo y completo como tal, pero se integra bien con herramientas de monitoreo de Kubernetes como Prometheus y Grafana. Podemos configurar exporters para capturar métricas de inferencia de KFServing (latencia, errores, volumen de solicitudes) y métricas específicas del modelo (por ejemplo, la distribución de predicciones).
PROBLEMA 01
Detección de Drift de Datos y Modelos
El rendimiento de un modelo puede degradarse con el tiempo debido a cambios en la distribución de los datos de entrada (drift de datos) o cambios en la relación entre las características y el objetivo (drift del concepto). Detectar esto de forma proactiva es fundamental.
SOLUCIÓN — Integración con Herramientas de Observabilidad de ML
Aunque Kubeflow no tiene un componente de drift nativo, se puede integrar con herramientas como Seldon Alibi Detect o evidently.ai para monitorear el drift. Estos pueden ejecutarse como contenedores sidecar o como un servicio separado, consumiendo los logs de inferencia del modelo. Por ejemplo, un contenedor sidecar podría capturar las solicitudes y respuestas de KFServing y enviarlas a un servicio de detección de drift.
# Ejemplo de configuración de un sidecar en InferenceService para capturar datos
apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: iris-classifier-drift
namespace: kubeflow
spec:
predictor:
containers:
- name: kserve-container # Contenedor principal del modelo (scikit-learn)
image: kserve/sklearnserver:v0.11.2 # Imagen pre-construida de KServe para sklearn
args: ["--model_dir", "/mnt/models"]
env:
- name: STORAGE_URI
value: "gs://your-model-bucket/iris-classifier/"
# Añadir un sidecar para la captura de datos
- name: data-capture-sidecar
image: your-org/data-capture-agent:latest # Su imagen personalizada
env:
- name: KSERVE_LOG_REQUESTS
value: "true" # Habilitar el log de KServe
- name: KSERVE_LOG_RESPONSE
value: "true"
volumeMounts:
- name: kserve-logs
mountPath: /var/log/kserve # Montar volumen para acceder a logs
# Configuración de volumen compartido para logs si es necesario
# volumes:
# - name: kserve-logs
# emptyDir: {}
La integración con Prometheus y Grafana es estándar en Kubernetes. KFServing expone métricas en formato Prometheus, que pueden ser recolectadas y visualizadas para tener una visión en tiempo real del rendimiento del modelo y la infraestructura.

Optimización de Hiperparámetros con Katib
Katib es el componente de Kubeflow para la optimización de hiperparámetros (HPO) y la búsqueda de arquitectura neuronal (NAS). Permite automatizar la búsqueda de los mejores hiperparámetros para un modelo dado, ejecutando múltiples experimentos en paralelo y utilizando algoritmos avanzados de búsqueda (ej. TPE, bayesiana, grid search).
EXPLICACIÓN DEL CÓDIGO
Este manifiesto YAML define un Experiment de Katib. Especifica la métrica objetivo a optimizar (por ejemplo, accuracy), el algoritmo de búsqueda (random), el rango de hiperparámetros a explorar y la plantilla para ejecutar cada «trial» (un entrenamiento con un conjunto específico de hiperparámetros).
apiVersion: "kubeflow.org/v1beta1"
kind: Experiment
metadata:
name: iris-hpo
namespace: kubeflow # O el namespace donde Kubeflow está instalado
spec:
objective:
type: Maximize
goal: 0.99
objectiveMetricName: accuracy
algorithm:
algorithmName: random
parameters:
- name: n_estimators
parameterType: int
feasibleSpace:
min: "50"
max: "200"
- name: max_depth
parameterType: int
feasibleSpace:
min: "5"
max: "15"
- name: learning_rate
parameterType: double
feasibleSpace:
min: "0.01"
max: "0.1"
trialTemplate:
primaryContainer: tf-mnist # Nombre del contenedor principal dentro del Pod del trial
trialParameters:
- name: n_estimators
description: "Number of estimators for RandomForest"
reference: n_estimators
- name: max_depth
description: "Max depth for RandomForest"
reference: max_depth
- name: learning_rate
description: "Learning rate for RandomForest"
reference: learning_rate
trialSpec:
apiVersion: batch/v1
kind: Job
spec:
template:
spec:
containers:
- name: tf-mnist
image: your-org/iris-trainer:latest # Imagen Docker de su código de entrenamiento
command:
- "python"
- "-m"
- "train_iris"
- "--n_estimators=$(trialParameters.n_estimators)"
- "--max_depth=$(trialParameters.max_depth)"
- "--learning_rate=$(trialParameters.learning_rate)"
# Su código de entrenamiento debe imprimir la métrica objetivo en stdout
# Katib la parseará para la optimización
restartPolicy: Never
Para ejecutar este experimento, guarde el YAML como katib-experiment.yaml y aplíquelo:
EXPLICACIÓN DEL CÓDIGO
Este comando inicia el experimento de Katib, que creará múltiples Pods (trials) para probar diferentes combinaciones de hiperparámetros.
kubectl apply -f katib-experiment.yaml
Katib gestionará la ejecución de los «trials» y le presentará los mejores conjuntos de hiperparámetros encontrados en su dashboard.
AVANZADO
7. Prácticas Avanzadas y CI/CD en MLOps con Kubeflow
Para un MLOps verdaderamente maduro en 2026, es esencial ir más allá de los pipelines básicos e integrar prácticas de CI/CD (Integración Continua/Despliegue Continuo) y gestión avanzada de datos y modelos.
CI/CD para Pipelines de ML
La integración de CI/CD en MLOps significa que cada cambio en el código del modelo, los datos o el pipeline desencadena automáticamente una serie de pruebas, entrenamiento y, potencialmente, un despliegue. Herramientas como Jenkins, GitLab CI/CD, GitHub Actions o Argo CD pueden ser utilizadas para orquestar este proceso.
Flujo de CI/CD Típico para MLOps con Kubeflow
1. Commit de Código — Un desarrollador o científico de datos envía cambios al repositorio de código fuente (Git).
2. Trigger de CI — El sistema de CI (ej. Jenkins) detecta el cambio y construye nuevas imágenes Docker para los componentes del pipeline.
3. Pruebas y Compilación del Pipeline — Se ejecutan pruebas unitarias y de integración. El pipeline de Kubeflow se compila a su formato YAML.
4. Despliegue del Pipeline — El pipeline compilado se sube a Kubeflow Pipelines para su ejecución. Esto puede incluir un reentrenamiento automático o manual.
5. Evaluación y Aprobación — Se evalúa el rendimiento del nuevo modelo. Si cumple con los criterios, se aprueba para el despliegue.
6. Despliegue del Modelo (CD) — El modelo aprobado se despliega en producción utilizando KFServing, potencialmente con estrategias de despliegue canary para minimizar riesgos.
Versionado de Datos y Modelos
La reproducibilidad es clave en MLOps. Esto no solo se aplica al código, sino también a los datos y los modelos. Herramientas como DVC (Data Version Control) permiten versionar conjuntos de datos y modelos junto con el código, utilizando Git. Esto asegura que siempre sepa qué versión de datos y código se utilizó para entrenar una versión específica de un modelo.
EXPLICACIÓN DEL CÓDIGO
Estos comandos demuestran cómo DVC versiona un conjunto de datos, lo almacena en un almacenamiento remoto (S3 en este caso) y crea un archivo .dvc ligero que se rastrea en Git. Esto permite que los pipelines de Kubeflow extraigan la versión correcta del conjunto de datos.
# Inicializar DVC en su repositorio Git
dvc init
# Configurar un almacenamiento remoto (ej. S3)
dvc remote add -d s3remote s3://your-dvc-bucket/data
# Añadir y versionar un conjunto de datos
dvc add data/raw_data.csv
# Empujar el conjunto de datos al almacenamiento remoto
dvc push
# El archivo data/raw_data.csv.dvc se añade a Git y se versiona.
# En un pipeline de Kubeflow, se usaría dvc pull para obtener los datos.
La combinación de Kubeflow Pipelines con DVC dentro de un flujo CI/CD crea un sistema MLOps altamente reproducible y auditable. Cada ejecución del pipeline está vinculada a versiones específicas de código y datos, lo que es invaluable para la depuración, la auditoría y la cumplimiento normativo.
DESAFÍOS
8. Desafíos Comunes y Mejores Prácticas
Aunque Kubeflow ofrece una potente suite de herramientas para MLOps, su implementación no está exenta de desafíos. Comprender estos obstáculos y aplicar las mejores prácticas puede marcar la diferencia entre el éxito y la frustración.
Desafíos Comunes
ADVERTENCIA
Complejidad de Kubernetes: Kubeflow se ejecuta sobre Kubernetes, lo que significa que se requiere un conocimiento sólido de Kubernetes para la instalación, configuración y resolución de problemas. La curva de aprendizaje puede ser empinada para equipos sin experiencia previa.
ADVERTENCIA
Gestión de Recursos: Las cargas de trabajo de ML pueden ser intensivas en recursos. Configurar correctamente los límites y solicitudes de CPU/GPU/memoria para los pods de Kubeflow es crucial para evitar cuellos de botella o un uso excesivo de recursos.
ADVERTENCIA
Actualizaciones y Versiones: Kubeflow evoluciona rápidamente. Mantenerse al día con las últimas versiones y gestionar las actualizaciones de componentes puede ser complejo, especialmente en entornos de producción.
Otros desafíos incluyen la gestión de datos a gran escala, la integración con sistemas de seguridad empresariales y la depuración de pipelines complejos.
Mejores Prácticas
Recomendaciones para el Éxito con Kubeflow
✓ Invertir en Conocimiento de Kubernetes: Capacite a su equipo en los fundamentos de Kubernetes. Esto es una inversión que pagará dividendos.
✓ Modularizar los Componentes: Diseñe componentes de pipeline pequeños, bien definidos y reutilizables. Esto mejora la mantenibilidad y la depuración.
✓ Versionado de Todo: Utilice DVC o herramientas similares para versionar datos y modelos, además de Git para el código. Metadata Store de KFP también ayuda aquí.
✓ Automatizar con CI/CD: Implemente un pipeline CI/CD robusto para automatizar la construcción, prueba y despliegue de sus pipelines y modelos.
✓ Monitoreo Integral: Combine el monitoreo de infraestructura (Prometheus/Grafana) con el monitoreo específico de ML (drift, rendimiento) para una visibilidad completa.
✓ Estrategias de Despliegue Avanzadas: Utilice las capacidades de KFServing para despliegues canary o blue-green para minimizar el riesgo en producción.
✓ Documentación y Estandarización: Documente sus pipelines, componentes y procesos. Establezca estándares para la codificación y la estructura de proyectos de ML.

COMPARATIVA
9. Kubeflow vs. Otros Frameworks MLOps: Un Análisis Comparativo
En el mercado de MLOps de 2026, Kubeflow no es la única opción. Existen diversas plataformas, tanto de código abierto como propietarias, que compiten por ofrecer soluciones integrales. Es crucial entender cómo se compara Kubeflow con algunas de las alternativas más populares para tomar una decisión informada.
Tabla Comparativa: Kubeflow, MLflow, Vertex AI y AWS SageMaker
A continuación, se presenta una tabla que compara las características clave de Kubeflow con otras plataformas MLOps prominentes: