

RESUMEN
Guía completa para generar imágenes con Stable Diffusion y Python en 2026
Domina la generación de imágenes con IA usando Stable Diffusion y Python.
Keywords: Stable Diffusion, Python, IA generativa
ÍNDICE
1. Introducción a Stable Diffusion y Python en 2026
2. Fundamentos Técnicos de Stable Diffusion
3. Configuración del Entorno de Desarrollo para IA Generativa
4. Generación Básica de Imágenes con Python
5. Técnicas Avanzadas de Control y Personalización
6. Optimización del Rendimiento y Gestión de Recursos
7. Resolución de Problemas Comunes
8. Aplicaciones Prácticas y Casos de Uso en 2026
9. Preguntas Frecuentes (FAQ)
10. Conclusión y Futuro de la Generación de Imágenes con IA
INTRODUCCIÓN
Introducción a Stable Diffusion y Python en 2026
La capacidad de generar imágenes a partir de texto ha revolucionado innumerables industrias, desde el diseño gráfico hasta la creación de contenido. En 2026, la tecnología ha avanzado a pasos agigantados, y herramientas como Stable Diffusion, cuando se combinan con la flexibilidad y potencia de Python, ofrecen un control sin precedentes sobre la creación visual. Esta guía completa está diseñada para desarrolladores, artistas y entusiastas de la inteligencia artificial que desean dominar la generación de imágenes con Stable Diffusion utilizando Python.
Exploraremos desde la configuración inicial del entorno hasta técnicas avanzadas de personalización y optimización, asegurando que puedas crear imágenes impresionantes y de alta calidad para tus proyectos. La evolución de los modelos de difusión latente ha hecho que esta tecnología sea más accesible y potente, y con Python como lenguaje de programación, las posibilidades son prácticamente ilimitadas.
PUNTO CLAVE
En 2026, Stable Diffusion con Python es la combinación ideal para un control granular y una generación de imágenes IA eficiente, abriendo nuevas fronteras para la creatividad y la automatización visual.
FUNDAMENTOS
Fundamentos Técnicos de Stable Diffusion
Para comprender cómo generar imágenes de manera efectiva con Stable Diffusion, es crucial entender su funcionamiento interno. Stable Diffusion es un modelo de difusión latente, una clase de modelos generativos que aprenden a «deshacer» un proceso de ruido para generar datos nuevos y coherentes. A diferencia de los modelos de difusión tradicionales que operan en el espacio de píxeles, Stable Diffusion trabaja en un espacio latente de menor dimensión, lo que reduce significativamente los requisitos computacionales y acelera la inferencia.
Arquitectura del Modelo
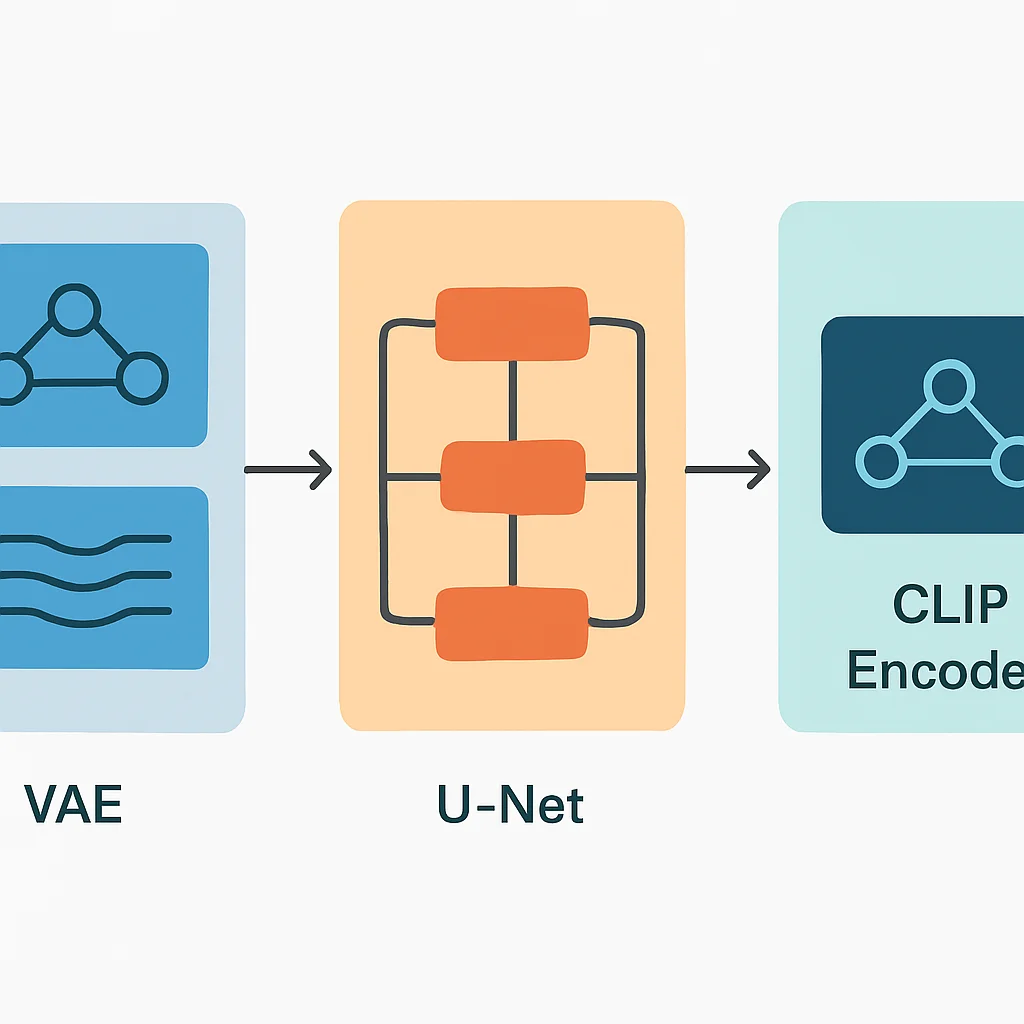
La arquitectura de Stable Diffusion se compone de varios componentes clave:
Componentes Clave
Codificador Variacional Automático (VAE) — Comprime imágenes en un espacio latente y las reconstruye. Es esencial para la eficiencia del modelo.
Red U-Net — El corazón del modelo de difusión, encargado de eliminar el ruido de la representación latente paso a paso.
Codificador de Texto (CLIP) — Transforma el texto de entrada (prompt) en una representación numérica que la U-Net puede entender para guiar el proceso de generación.
Programador de Ruido (Scheduler) — Determina cómo se añade y se elimina el ruido en cada paso de la difusión, influyendo en la calidad y velocidad de la generación.
El proceso comienza con un prompt de texto que el codificador CLIP convierte en un vector. Paralelamente, se genera un tensor de ruido aleatorio en el espacio latente. La U-Net utiliza el vector del prompt para guiar la eliminación iterativa del ruido del tensor latente. Una vez que el ruido se ha reducido lo suficiente, el decodificador VAE transforma la representación latente limpia de nuevo en una imagen de píxeles de alta resolución.
Evolución y Estado en 2026
Desde su lanzamiento inicial, Stable Diffusion ha visto múltiples iteraciones. En 2026, los modelos más recientes, como SDXL Turbo o variantes especializadas, ofrecen una calidad de imagen excepcional, mayor coherencia y la capacidad de generar imágenes en resoluciones nativas más altas (ej., 1024×1024 o 2048×2048) con menos pasos de inferencia. La comunidad de código abierto ha contribuido con miles de modelos finetuneados (checkpoints), LoRAs y ControlNets, expandiendo enormemente las capacidades del modelo base.
La integración con librerías de Python como Hugging Face Diffusers ha simplificado enormemente el desarrollo, permitiendo a los usuarios cargar y utilizar diferentes modelos con solo unas pocas líneas de código. Esto ha democratizado el acceso a la IA generativa, haciendo posible que incluso proyectos pequeños implementen capacidades de generación de imágenes de vanguardia.
CONFIGURACIÓN
Configuración del Entorno de Desarrollo para IA Generativa
Antes de sumergirnos en la generación de imágenes, necesitamos configurar un entorno de desarrollo robusto. Para trabajar con Stable Diffusion en 2026, se recomienda tener acceso a una GPU compatible con CUDA (NVIDIA) o ROCm (AMD), ya que la generación de imágenes es una tarea computacionalmente intensiva. Aunque es posible ejecutarla en CPU, los tiempos de inferencia serán considerablemente más largos (minutos vs. segundos).
Requisitos de Hardware y Software
Para una experiencia óptima, recomendamos:
- GPU: NVIDIA RTX 3060 (12GB VRAM) o superior. Para SDXL, se recomiendan 16GB de VRAM o más.
- RAM: 16GB o más.
- Almacenamiento: SSD con al menos 100GB libres para modelos y resultados.
- Sistema Operativo: Windows 10/11, Ubuntu 22.04+ o macOS (para chips Apple Silicon).
- Controladores de GPU: Asegúrate de tener los controladores más recientes y el toolkit CUDA instalado si usas NVIDIA.
Instalación de Python y Librerías Esenciales
Comenzaremos instalando Python (versión 3.9 o superior es ideal) y creando un entorno virtual para gestionar nuestras dependencias.
EXPLICACIÓN DEL CÓDIGO
Estos comandos inicializan un entorno virtual de Python, lo activan y luego instalan las librerías principales necesarias para Stable Diffusion: diffusers (la interfaz de Hugging Face), transformers (para el codificador de texto), accelerate (para optimización de GPU) y torch (el framework de aprendizaje profundo).
# Crear y activar un entorno virtual
python -m venv sd_env
# En Windows:
.\sd_env\Scripts\activate
# En macOS/Linux:
source sd_env/bin/activate
# Instalar PyTorch (asegúrate de que sea la versión con soporte CUDA si tienes GPU NVIDIA)
# Visita https://pytorch.org/get-started/locally/ para la versión más reciente
# Ejemplo para CUDA 12.1:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
# Instalar las librerías de Hugging Face
pip install diffusers transformers accelerate scipyUna vez instaladas, tu entorno está listo para interactuar con los modelos de Stable Diffusion.
Descarga de Modelos de Stable Diffusion
Los modelos de Stable Diffusion se alojan comúnmente en el Hugging Face Hub. Para esta guía, utilizaremos un modelo base como stabilityai/stable-diffusion-xl-base-1.0, que es uno de los modelos SDXL más potentes y versátiles en 2026. La librería diffusers se encargará de descargar los pesos del modelo automáticamente la primera vez que lo uses.
PUNTO CLAVE
Siempre es recomendable usar entornos virtuales de Python para aislar las dependencias de tus proyectos y evitar conflictos entre librerías. Para Stable Diffusion, una GPU con al menos 12GB de VRAM es casi indispensable.
GENERACIÓN BÁSICA
Generación Básica de Imágenes con Python
Con el entorno configurado, estamos listos para generar nuestra primera imagen. El proceso es sorprendentemente sencillo gracias a la abstracción que ofrece la librería diffusers.
Primer Ejemplo: Text-to-Image (T2I)
Aquí tienes un script básico de Python para generar una imagen a partir de un prompt de texto. Usaremos el modelo SDXL para obtener resultados de alta calidad.
EXPLICACIÓN DEL CÓDIGO
Este script importa la clase DiffusionPipeline, carga el modelo SDXL, define un prompt y un prompt negativo para guiar la generación, y luego invoca el pipeline para crear una imagen. Finalmente, guarda la imagen generada en un archivo PNG.
from diffusers import DiffusionPipeline
import torch
# Cargar el pipeline de Stable Diffusion XL
# Asegúrate de tener suficiente VRAM (al menos 12GB, idealmente 16GB para SDXL)
# Usamos dtype=torch.float16 para reducir el uso de memoria y acelerar la inferencia
pipe = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16"
)
pipe.to("cuda") # Mover el pipeline a la GPU
# Definir el prompt y el prompt negativo
prompt = "Un astronauta en un caballo galopando sobre la luna, estilo fotorrealista, iluminación cinematográfica, 8k"
negative_prompt = "baja calidad, borroso, distorsionado, feo, mal dibujado, deforme, extraño, duplicado"
# Generar la imagen
# num_inference_steps: Más pasos = más detalle (pero más lento), 20-30 es un buen balance para SDXL
# guidance_scale: Qué tan fuerte el modelo sigue el prompt (7-9 es común)
image = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
num_inference_steps=25,
guidance_scale=7.5
).images[0]
# Guardar la imagen
image.save("astronauta_luna_sdxl.png")
print("Imagen generada y guardada como astronauta_luna_sdxl.png")Al ejecutar este script, verás cómo diffusers descarga el modelo (si es la primera vez) y luego genera la imagen. El proceso puede tomar desde unos pocos segundos hasta un minuto, dependiendo de tu GPU.
Parámetros Clave para la Generación
Los parámetros num_inference_steps y guidance_scale son fundamentales para controlar el resultado:
num_inference_steps: Cuantas más iteraciones, más tiempo tarda pero potencialmente mayor detalle y coherencia. Para SDXL, 20-30 pasos suelen ser suficientes. Para modelos más antiguos, 50-100 pasos eran comunes.guidance_scale(o CFG Scale): Controla la influencia del prompt en la imagen. Valores más altos (ej. 10-15) hacen que la imagen se ajuste más al prompt, pero pueden generar artefactos o imágenes menos creativas. Valores más bajos (ej. 5-7) dan más libertad al modelo.seed: Un número entero para inicializar el generador de números aleatorios. Usar el mismo seed con el mismo prompt y parámetros garantiza la replicabilidad de la imagen.
PUNTO CLAVE
El «prompt engineering» es un arte. Experimenta con diferentes formulaciones y prompts negativos para guiar a Stable Diffusion hacia los resultados deseados. La claridad, el detalle y el uso de palabras clave específicas son cruciales.

AVANZADO
Técnicas Avanzadas de Control y Personalización
La generación básica es solo el principio. Stable Diffusion, especialmente en 2026, ofrece un ecosistema rico en herramientas y técnicas para un control mucho mayor sobre el proceso de creación. Exploraremos algunas de las más poderosas.
ControlNet y T2I-Adapter
ControlNet y T2I-Adapter son extensiones revolucionarias que permiten guiar la generación de imágenes utilizando entradas adicionales como poses humanas (OpenPose), mapas de profundidad, contornos (Canny), o bocetos. Esto significa que puedes controlar la composición, la pose de los personajes, la profundidad de campo y otros aspectos estructurales con una precisión asombrosa.
ControlNet: Casos de Uso Comunes
OpenPose — Controlar la pose de figuras humanas o animales en la imagen generada.
Canny Edge — Generar imágenes que sigan los contornos de una imagen de entrada.
Depth Map — Mantener la profundidad y la estructura espacial de una escena de referencia.
Normal Map — Preservar la información de la superficie y la iluminación de una imagen.
Scribble/Sketch — Convertir bocetos a mano alzada en imágenes detalladas.
Para usar ControlNet, necesitarás cargar un modelo de ControlNet junto con tu pipeline principal de Stable Diffusion. La librería diffusers soporta esto de manera fluida.
EXPLICACIÓN DEL CÓDIGO
Este fragmento muestra cómo integrar un ControlNet (en este caso, Canny) en tu pipeline. Primero, cargas la imagen de control (un mapa Canny). Luego, inicializas el ControlNetModel y lo combinas con el StableDiffusionXLControlNetPipeline. Finalmente, pasas la imagen de control al pipeline para guiar la generación.
from diffusers import StableDiffusionXLControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
from diffusers.utils import load_image
import torch
from PIL import Image
import cv2
import numpy as np
# Cargar una imagen de entrada para generar un mapa Canny
image_url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/person.png"
original_image = load_image(image_url).resize((1024, 1024))
# Preprocesar la imagen para obtener los bordes Canny
image_np = np.array(original_image)
image_np = cv2.Canny(image_np, 100, 200) # Aplicar filtro Canny
image_np = image_np[:, :, None]
image_np = np.concatenate([image_np, image_np, image_np], axis=2)
canny_image = Image.fromarray(image_np)
# Cargar el modelo ControlNet (ej. Canny para SDXL)
controlnet = ControlNetModel.from_pretrained(
"diffusers/controlnet-canny-sdxl-1.0",
torch_dtype=torch.float16
)
# Cargar el pipeline con ControlNet
pipe = StableDiffusionXLControlNetPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
controlnet=controlnet,
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16"
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.to("cuda")
# Generar la imagen con ControlNet
prompt_controlnet = "Una persona caminando por un bosque, estilo arte digital, vibrante"
image_controlled = pipe(prompt_controlnet, canny_image, num_inference_steps=25).images[0]
image_controlled.save("persona_bosque_canny.png")
print("Imagen con ControlNet generada y guardada como persona_bosque_canny.png")Image-to-Image (img2img) e Inpainting/Outpainting
Estas técnicas permiten modificar imágenes existentes en lugar de generarlas desde cero. img2img toma una imagen de entrada y un prompt, transformando la imagen original según las indicaciones del texto. Inpainting permite rellenar partes faltantes o modificar áreas específicas de una imagen usando una máscara, mientras que outpainting extiende la imagen más allá de sus límites originales. Para estas tareas, se utilizan pipelines específicos como StableDiffusionImg2ImgPipeline o StableDiffusionInpaintPipeline.
LoRA (Low-Rank Adaptation) y Modelos Finetuneados
Los modelos LoRA son pequeños archivos que se aplican sobre un modelo base de Stable Diffusion para añadir un estilo, personaje o concepto específico sin tener que entrenar un modelo completo desde cero. Son increíblemente eficientes y populares en 2026 para personalizar la salida de la IA. Puedes cargar LoRAs junto con tu pipeline principal para infundir un estilo particular en tus generaciones.
PUNTO CLAVE
La combinación de ControlNet y LoRA ofrece un nivel de control y personalización sin precedentes. ControlNet define la estructura y composición, mientras que LoRA refina el estilo o la identidad de los elementos dentro de esa estructura.
OPTIMIZACIÓN
Optimización del Rendimiento y Gestión de Recursos
La generación de imágenes con IA puede ser intensiva en recursos. Es crucial optimizar tu configuración para obtener las mejores velocidades de inferencia y gestionar eficazmente la memoria de la GPU, especialmente con modelos grandes como SDXL.
Técnicas de Reducción de Memoria y Aceleración
Aquí hay algunas estrategias clave para mejorar el rendimiento:
- Precisión Mixta (FP16): Usar
torch_dtype=torch.float16al cargar el pipeline reduce el uso de VRAM a la mitad y acelera la inferencia en GPUs modernas. Es la optimización más importante. - xFormers: Una biblioteca de atención eficiente que reduce el uso de memoria y acelera las operaciones de atención dentro del modelo. Se instala con
pip install xformersy se activa conpipe.enable_xformers_memory_efficient_attention(). - Gradient Checkpointing: Una técnica que intercambia la velocidad por la memoria, útil para GPUs con VRAM muy limitada. Se activa con
pipe.enable_gradient_checkpointing(). - Offloading (CPU/GPU): Para GPUs con VRAM extremadamente baja, puedes descargar partes del modelo a la CPU cuando no están en uso. Esto se hace con
pipe.enable_sequential_cpu_offload()opipe.enable_model_cpu_offload().
EXPLICACIÓN DEL CÓDIGO
Este ejemplo muestra cómo habilitar xFormers para la atención eficiente en tu pipeline de Stable Diffusion XL. Asegúrate de haber instalado xformers previamente.
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16"
)
# Habilitar atención eficiente con xFormers
# Asegúrate de que xformers esté instalado: pip install xformers
try:
pipe.enable_xformers_memory_efficient_attention()
print("xFormers habilitado para optimización de memoria.")
except ImportError:
print("xFormers no está instalado o no es compatible. La generación continuará sin esta optimización.")
pipe.to("cuda")
prompt_optimized = "Un dragón volando sobre un castillo en ruinas al atardecer, arte fantástico, detallado"
image_optimized = pipe(prompt_optimized, num_inference_steps=25).images[0]
image_optimized.save("dragon_optimizado.png")
print("Imagen optimizada generada y guardada como dragon_optimizado.png")Monitoreo de Recursos
Para entender el impacto de estas optimizaciones, es útil monitorear el uso de tu GPU. Herramientas como nvidia-smi (para NVIDIA) o gestores de tareas del sistema te darán una visión en tiempo real del uso de VRAM y la carga de la GPU. Comparar los tiempos de inferencia y el consumo de memoria con y sin optimizaciones te ayudará a encontrar la configuración ideal para tu hardware.
PUNTO CLAVE
La optimización con float16 y xFormers puede reducir el uso de VRAM en un 30-50% y acelerar la generación hasta un 20-30% en hardware compatible, lo que es crucial para flujos de trabajo eficientes en 2026.
PROBLEMAS Y SOLUCIONES
Resolución de Problemas Comunes
A pesar de la robustez de las librerías modernas, es posible encontrarse con desafíos al trabajar con Stable Diffusion y Python. Aquí abordamos algunos de los problemas más frecuentes y sus soluciones.
PROBLEMA 01
Errores de Memoria de GPU (CUDA Out Of Memory)
Este es el problema más común, especialmente al usar modelos grandes como SDXL o al intentar generar imágenes de alta resolución en GPUs con VRAM limitada (menos de 12GB).
SOLUCIÓN — Optimización de VRAM
- Asegúrate de usar
torch_dtype=torch.float16al cargar el pipeline. - Habilita
pipe.enable_xformers_memory_efficient_attention(). - Considera
pipe.enable_model_cpu_offload()si tienes muy poca VRAM. - Reduce la resolución de la imagen generada inicialmente y luego usa técnicas de escalado (upscaling) de IA.
- Cierra otras aplicaciones que puedan estar usando VRAM de tu GPU.
PROBLEMA 02
Imágenes de Baja Calidad o Irrelevantes
Las imágenes generadas no cumplen con las expectativas o no reflejan el prompt.
SOLUCIÓN — Mejora del Prompt Engineering
- Sé más específico y descriptivo en tu prompt. Incluye detalles sobre estilo, iluminación, composición, etc.
- Utiliza prompts negativos para eliminar elementos no deseados (ej., «deformed, blurry, ugly»).
- Experimenta con
guidance_scale(CFG Scale). Valores entre 7 y 9 suelen ser un buen punto de partida para SDXL. - Aumenta
num_inference_steps(hasta 30-50 para SDXL) para dar más tiempo al modelo para refinar la imagen. - Prueba con diferentes «seeds» para explorar variaciones del mismo prompt.
PROBLEMA 03
Problemas de Instalación o Dependencias
Errores al instalar PyTorch, diffusers o conflictos entre librerías.
SOLUCIÓN — Verificación del Entorno
- Asegúrate de que estás en un entorno virtual activado.
- Verifica que la versión de PyTorch que instalaste sea compatible con tu versión de CUDA (si usas NVIDIA). Consulta la página de inicio de PyTorch.
- Actualiza pip (
python -m pip install --upgrade pip). - Si un problema persiste, intenta reinstalar las librerías en un entorno virtual nuevo.
- Consulta la documentación de Hugging Face Diffusers para requisitos específicos y notas de compatibilidad.
APLICACIONES
Aplicaciones Prácticas y Casos de Uso en 2026
La capacidad de generar imágenes de alta calidad con Stable Diffusion y Python ha abierto un abanico de posibilidades en diversas industrias. En 2026, la IA generativa se ha integrado profundamente en muchos flujos de trabajo creativos y técnicos.
Casos de Uso Innovadores
1. Generación de Activos para Videojuegos
Creación rápida de texturas, sprites, fondos o incluso conceptos de personajes basados en descripciones de texto o bocetos. Esto acelera significativamente el ciclo de desarrollo.
2. Diseño Gráfico y Publicidad
Generación de imágenes para campañas publicitarias, banners, ilustraciones de sitios web o prototipos de diseño. Los diseñadores pueden iterar ideas visuales mucho más rápido.
3. Arte Digital y Concept Art
Artistas pueden usar Stable Diffusion para explorar nuevas ideas, generar fondos complejos o crear obras de arte únicas, combinando su visión con la capacidad generativa de la IA.
4. Personalización de Contenido
Creación de imágenes altamente personalizadas para usuarios individuales en plataformas de comercio electrónico, redes sociales o experiencias interactivas.
5. Prototipado y Visualización Arquitectónica
Generación rápida de visualizaciones de diseños arquitectónicos interiores y exteriores, paisajismo o prototipos de productos a partir de bocetos y descripciones.
La integración de Stable Diffusion con Python permite a los desarrolladores crear herramientas y aplicaciones personalizadas que aprovechan estas capacidades. Por ejemplo, se pueden construir APIs para la generación de imágenes bajo demanda, sistemas de recomendación visual o herramientas de edición de imágenes asistidas por IA.

PUNTO CLAVE
En 2026, la IA generativa no solo crea arte, sino que se ha convertido en una herramienta esencial para la productividad, la innovación y la personalización en sectores creativos y técnicos.
Preguntas Frecuentes (FAQ)
Q. ¿Qué hardware necesito para ejecutar Stable Diffusion con Python en 2026?
Para una experiencia fluida con los modelos actuales de Stable Diffusion (especialmente SDXL), se recomienda una GPU NVIDIA con al menos 12GB de VRAM, preferiblemente 16GB o más. También es útil tener 16GB de RAM y un SSD rápido.
Q. ¿Es Stable Diffusion gratuito y de código abierto?
Sí, Stable Diffusion es de código abierto y sus modelos base son generalmente de uso gratuito, incluso para fines comerciales, bajo licencias específicas (como CreativeML Open RAIL-M). Esto ha sido un motor clave para su adopción y desarrollo en 2026.
Q. ¿Cuál es la mejor forma de mejorar la calidad de mis imágenes generadas?
Para mejorar la calidad, enfócate en el prompt engineering (prompts detallados y negativos efectivos), ajusta la guidance_scale, aumenta num_inference_steps, y utiliza técnicas avanzadas como ControlNet o LoRA para un control más preciso del estilo y la composición.
Q. ¿Puedo usar Stable Diffusion para modificar mis propias imágenes?
Absolutamente. Stable Diffusion ofrece capacidades como Image-to-Image (img2img), inpainting y outpainting que te permiten transformar, editar o expandir imágenes existentes utilizando prompts de texto y máscaras.
Q. ¿Qué papel juega Python en la generación de imágenes con Stable Diffusion?
Python es el lenguaje de programación principal para interactuar con Stable Diffusion, gracias a librerías como Hugging Face Diffusers. Permite un control programático completo sobre la carga de modelos, la configuración de parámetros, la ejecución de pipelines y la integración con otras herramientas de IA o flujos de trabajo personalizados.
CONCLUSIÓN
Conclusión y Futuro de la Generación de Imágenes con IA
Hemos recorrido un camino completo, desde la configuración del entorno hasta la generación avanzada y la optimización de imágenes con Stable Diffusion y Python. En 2026, la IA generativa no es solo una curiosidad tecnológica, sino una herramienta indispensable que redefine la creatividad digital y la eficiencia en diversos campos. La combinación de la potencia de Stable Diffusion y la flexibilidad de Python te dota de las habilidades para crear visuales impresionantes y personalizados, abriendo un universo de posibilidades para tus proyectos.
El futuro de la generación de imágenes con IA es brillante y está en constante evolución. Podemos esperar ver modelos aún más eficientes, intuitivos y con mayor capacidad de control. La integración con otras modalidades de IA (como el audio o el vídeo) será cada vez más fluida, y las consideraciones éticas en torno a la autoría y el uso responsable de la IA seguirán siendo un tema central. Mantenerse al día con estas tecnologías no solo es emocionante, sino esencial para cualquier profesional en el ámbito tecnológico y creativo.
Esperamos que esta guía te sirva como un punto de partida sólido para explorar y dominar el fascinante mundo de la generación de imágenes con Stable Diffusion y Python.
¡Gracias por leer!
Esperamos que esta guía te haya sido de gran utilidad para iniciar o profundizar en el mundo de la generación de imágenes con Stable Diffusion y Python.
¿Preguntas o comentarios? ¡Déjalos abajo!