
RESUMEN
Estrategias de DR y HA en la Nube 2026
Guía esencial para implementar recuperación ante desastres y alta disponibilidad en entornos cloud.
Keywords: Recuperación ante desastres, Alta Disponibilidad, Cloud Computing
ÍNDICE
1. La Importancia Crítica de la Resiliencia Cloud en 2026
2. Fundamentos de Recuperación ante Desastres (DR) y Alta Disponibilidad (HA)
3. Estrategias de Recuperación ante Desastres en la Nube
4. Estrategias de Alta Disponibilidad en la Nube
5. Implementación de DR y HA en los Principales Proveedores Cloud (AWS, Azure, GCP)
6. Desafíos Comunes y Soluciones en la Implementación de DR/HA
7. Guía Práctica para Diseñar tu Estrategia de Resiliencia Cloud
8. Preguntas Frecuentes
1. La Importancia Crítica de la Resiliencia Cloud en 2026
En el panorama tecnológico actual, la dependencia de las empresas en los servicios en la nube es más pronunciada que nunca. A medida que las infraestructuras se vuelven más complejas y distribuidas, la necesidad de contar con estrategias de Recuperación ante Desastres y Alta Disponibilidad en la Nube 2026 robustas se ha convertido en un pilar fundamental para la continuidad del negocio. Un fallo, por mínimo que sea, puede traducirse en pérdidas financieras significativas, daños a la reputación y una interrupción severa en la experiencia del usuario. En 2026, con la creciente adopción de arquitecturas serverless, microservicios y contenedores, la gestión de la resiliencia no es solo una buena práctica, sino un requisito indispensable para operar de manera competitiva y segura.
La interrupción de servicios, ya sea por fallos de hardware, errores humanos, ciberataques o desastres naturales, es una amenaza constante. Un estudio reciente de Statista indica que el costo promedio de una hora de inactividad para una empresa puede superar los $300,000 USD, y para algunas organizaciones de misión crítica, esta cifra puede ascender a millones. Estos números resaltan la urgencia de implementar soluciones que garanticen que las aplicaciones y los datos permanezcan accesibles y operativos, incluso frente a las adversidades más severas. Nuestro enfoque en este artículo es desglosar las metodologías y herramientas que los equipos de DevOps pueden emplear para construir infraestructuras cloud verdaderamente resilientes.
PUNTO CLAVE
La resiliencia cloud en 2026 no es un lujo, sino una necesidad estratégica para proteger la reputación, los ingresos y la continuidad operativa frente a un entorno de amenazas cada vez más complejo.
2. Fundamentos de Recuperación ante Desastres (DR) y Alta Disponibilidad (HA)
Antes de sumergirnos en las estrategias específicas, es crucial comprender la diferencia entre Recuperación ante Desastres (DR) y Alta Disponibilidad (HA), aunque a menudo se usen indistintamente. Ambos conceptos buscan minimizar el tiempo de inactividad, pero abordan diferentes escalas de fallo y objetivos.
2.1. Recuperación ante Desastres (DR)
La Recuperación ante Desastres se enfoca en restaurar las operaciones después de un evento catastrófico que ha causado una interrupción significativa de los servicios, como un fallo de región completa, una pérdida masiva de datos o un ciberataque devastador. El objetivo principal es recuperar la funcionalidad del sistema en una ubicación alternativa o con recursos restaurados.
Los dos parámetros clave en DR son:
RTO (Recovery Time Objective): Es el tiempo máximo aceptable que una aplicación o servicio puede estar inactivo después de un desastre. Por ejemplo, un RTO de 4 horas significa que el sistema debe estar completamente operativo en menos de 4 horas.
RPO (Recovery Point Objective): Es la cantidad máxima de datos que una aplicación puede permitirse perder, medida en tiempo. Un RPO de 15 minutos significa que se puede perder un máximo de 15 minutos de datos desde el momento del desastre hasta la última copia de seguridad o replicación.
2.2. Alta Disponibilidad (HA)
La Alta Disponibilidad se refiere a la capacidad de un sistema para permanecer operativo y accesible con una interrupción mínima o nula, incluso frente a fallos de componentes individuales (servidores, discos, redes). Se centra en la redundancia y la conmutación por error automática dentro de una misma región o centro de datos para evitar que un único punto de fallo detenga el servicio.
Los mecanismos comunes de HA incluyen:
Redundancia: Duplicación de componentes críticos (servidores, bases de datos, redes) para que si uno falla, otro pueda tomar el relevo.
Conmutación por Error (Failover): Proceso automático de transferencia del control a un componente redundante cuando el primario falla.
Balanceo de Carga: Distribución del tráfico entre múltiples instancias para mejorar el rendimiento y la tolerancia a fallos.
PUNTO CLAVE
Mientras que HA previene interrupciones a pequeña escala dentro de una región, DR prepara la recuperación completa de una interrupción a gran escala que afecta a toda una región o sistema principal.
3. Estrategias de Recuperación ante Desastres en la Nube
Los proveedores de la nube ofrecen una gama flexible de modelos para la Recuperación ante Desastres, permitiendo a las organizaciones elegir la estrategia que mejor se adapte a sus RTO/RPO y presupuestos. A continuación, exploramos los modelos más comunes, desde los más económicos hasta los de mayor resiliencia.
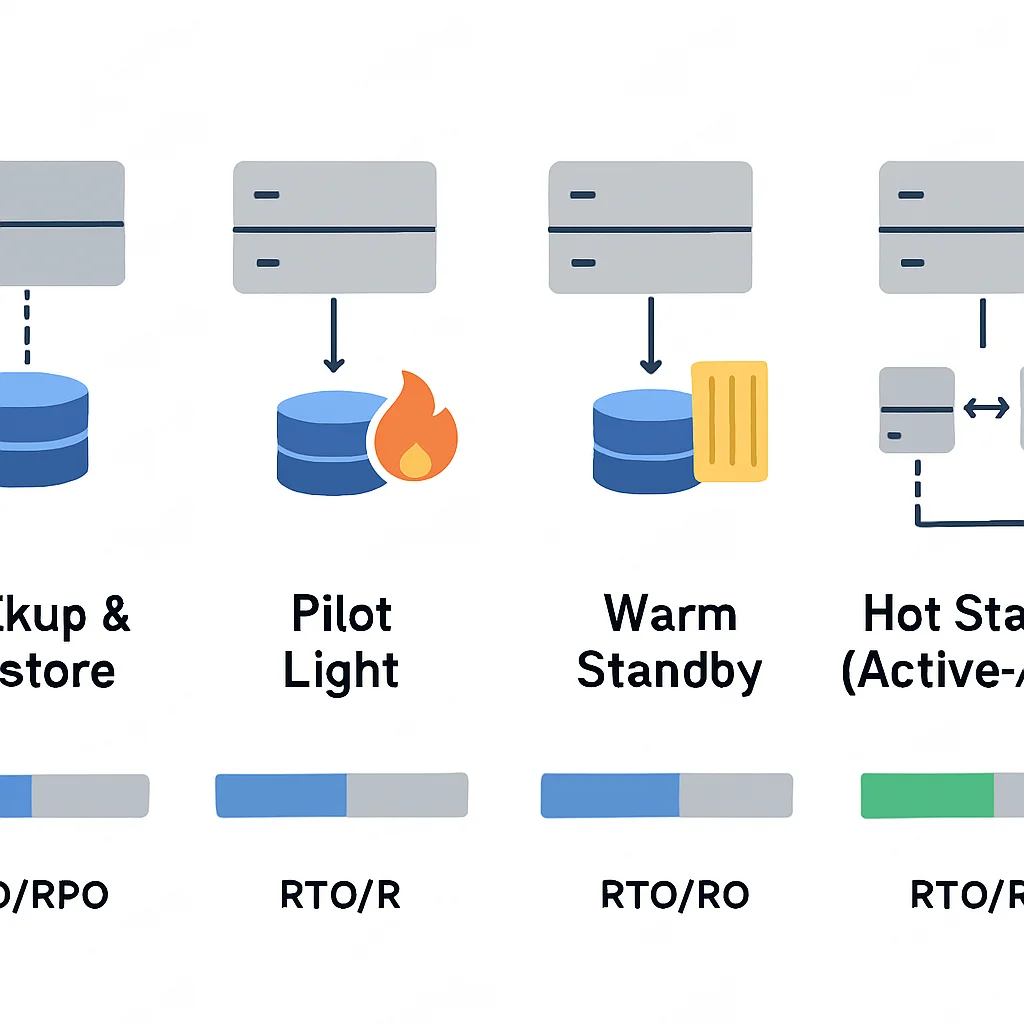
3.1. Backup y Restauración
Esta es la estrategia de DR más básica y económica. Implica realizar copias de seguridad regulares de los datos y configuraciones en una ubicación separada (a menudo un almacenamiento de objetos en la nube, como AWS S3, Azure Blob Storage o Google Cloud Storage). En caso de desastre, los datos se restauran en una nueva infraestructura. Los RTO y RPO son generalmente altos con esta estrategia, ya que la restauración puede llevar horas o incluso días, y solo se puede recuperar hasta el punto de la última copia de seguridad.
Casos de Uso: Aplicaciones no críticas, datos de archivo, entornos de desarrollo/prueba.
3.2. Piloto Frío (Pilot Light)
En el modelo de Piloto Frío, se replican los datos esenciales y se mantiene un conjunto mínimo de recursos de infraestructura en la región de recuperación. La infraestructura principal se apaga o se escala a cero para minimizar costos, manteniendo solo los componentes «siempre encendidos» (como bases de datos replicadas o servidores de autenticación) que son necesarios para arrancar rápidamente. Cuando ocurre un desastre, se «enciende» el resto de la infraestructura, se escala y se redirige el tráfico. Ofrece RTO y RPO mejorados en comparación con el backup y restauración.
Casos de Uso: Aplicaciones críticas que pueden tolerar algunas horas de inactividad, recuperación de bases de datos.
3.3. Espera Templada (Warm Standby)
La estrategia de Espera Templada implica mantener una réplica de la infraestructura principal en una región de recuperación, pero a menor escala o con menos capacidad. Los datos se replican continuamente, y las instancias están en ejecución, listas para recibir tráfico. En caso de desastre, se escala la infraestructura de espera templada y se redirige el tráfico. Los RTO y RPO son significativamente más bajos que los de Piloto Frío, generalmente en minutos u horas, pero con un costo operativo más alto.
Casos de Uso: Aplicaciones de misión crítica que requieren un RTO y RPO bajos, servicios que no pueden permitirse una interrupción prolongada.
3.4. Espera Caliente (Hot Standby / Multi-Sitio Activo-Activo)
Este es el modelo de DR más avanzado y costoso, pero ofrece los RTO y RPO más bajos, a menudo cercanos a cero. La infraestructura completa se replica en una región de recuperación, y ambas regiones están activas y procesando tráfico simultáneamente (activo-activo) o una está activa y la otra en espera idéntica (activo-pasivo). La conmutación por error es casi instantánea y transparente para el usuario. Requiere una replicación de datos síncrona o asíncrona de muy baja latencia.
Casos de Uso: Aplicaciones de misión crítica con requisitos de disponibilidad extrema, servicios financieros, comercio electrónico de alto volumen.
PUNTO CLAVE
La elección de la estrategia de DR depende directamente de los RTO/RPO aceptables y del presupuesto. Una buena práctica es segmentar las aplicaciones según su criticidad y aplicar diferentes estrategias.
4. Estrategias de Alta Disponibilidad en la Nube
La Alta Disponibilidad se construye a nivel de componentes individuales y de la arquitectura dentro de una región cloud. Los proveedores de nube ofrecen herramientas y servicios inherentes para lograr HA con facilidad.
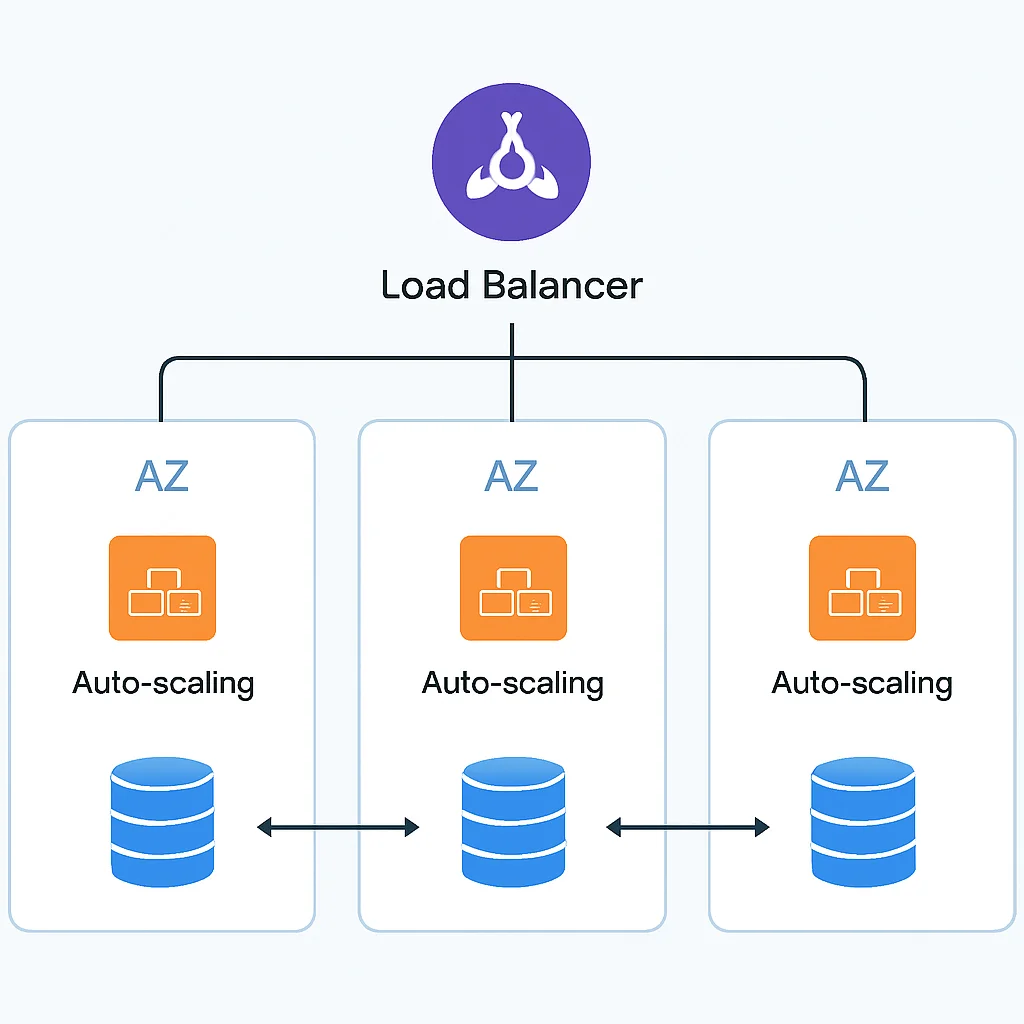
4.1. Zonas de Disponibilidad (AZs)
Las Zonas de Disponibilidad son centros de datos aislados físicamente dentro de una misma región, conectados por enlaces de red de baja latencia. Desplegar aplicaciones y bases de datos a través de múltiples AZs protege contra fallos de un solo centro de datos (p. ej., corte de energía, inundación). Si una AZ falla, el tráfico se redirige automáticamente a las instancias en otras AZs.
Ejemplo: Un clúster de bases de datos o un grupo de instancias de servidores web distribuidos entre 3 AZs.
4.2. Balanceo de Carga
Los balanceadores de carga distribuyen el tráfico de red de entrada entre múltiples servidores o instancias de aplicación. Esto no solo mejora el rendimiento y la escalabilidad, sino que también proporciona HA al desviar automáticamente el tráfico de instancias con fallos a instancias saludables. Son cruciales para arquitecturas de microservicios y aplicaciones web.
Ejemplo: AWS Elastic Load Balancer (ELB), Azure Load Balancer, Google Cloud Load Balancing.
4.3. Autoescalado (Auto Scaling)
El autoescalado ajusta automáticamente el número de instancias de computación en función de la demanda o las métricas de rendimiento. Para HA, el autoescalado puede reemplazar automáticamente instancias con fallos, asegurando que siempre haya suficientes recursos disponibles para manejar la carga de trabajo, incluso si algunas instancias dejan de funcionar.
Ejemplo: AWS Auto Scaling Groups, Azure Virtual Machine Scale Sets, Google Cloud Managed Instance Groups.
4.4. Bases de Datos Replicadas y Multi-AZ
Las bases de datos son a menudo el punto más crítico para la HA. Los proveedores de la nube ofrecen opciones como bases de datos gestionadas con replicación síncrona entre AZs (por ejemplo, AWS RDS Multi-AZ, Azure SQL Database Geo-replication, Google Cloud Spanner Multi-Region). Esto garantiza que si la instancia principal falla, una réplica se promueve automáticamente a principal con una pérdida de datos mínima o nula y un tiempo de inactividad muy bajo.
Ejemplo: Desplegar una instancia de PostgreSQL en AWS RDS con la opción Multi-AZ activada.
PUNTO CLAVE
Combinar Zonas de Disponibilidad, balanceadores de carga y autoescalado es la base para construir arquitecturas de Alta Disponibilidad robustas en la nube.
5. Implementación de DR y HA en los Principales Proveedores Cloud (AWS, Azure, GCP)
Cada proveedor de nube ofrece un conjunto de servicios y características que facilitan la implementación de estrategias de DR y HA. Aunque los conceptos son los mismos, la terminología y las herramientas específicas varían.
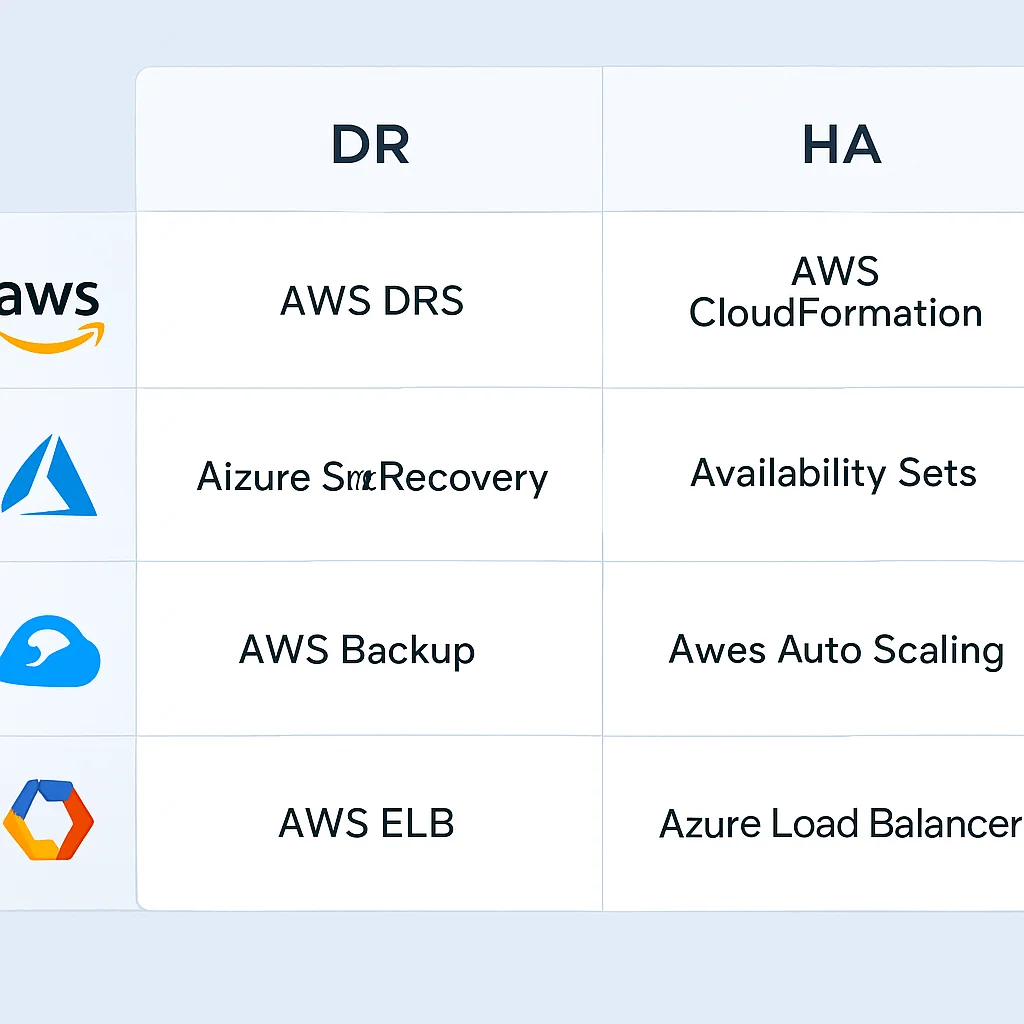
5.1. Amazon Web Services (AWS)
AWS es pionero en la infraestructura global con Regiones y Zonas de Disponibilidad (AZs). Sus servicios clave para DR y HA incluyen:
HA:
• Elastic Load Balancing (ELB): Distribuye el tráfico a través de múltiples instancias y AZs.
• Auto Scaling Groups (ASG): Mantiene el número deseado de instancias y las reemplaza automáticamente si fallan.
• Amazon RDS Multi-AZ: Replicación síncrona de bases de datos entre AZs para failover automático.
DR:
• AWS Backup: Servicio centralizado para copias de seguridad de diversos recursos.
• Amazon S3 Cross-Region Replication (CRR): Replicación automática de objetos S3 a otra región.
• Amazon Route 53 DNS Failover: Redirecciona el tráfico a un endpoint secundario en caso de fallo del primario.
• AWS Elastic Disaster Recovery (DRS): Servicio de recuperación ante desastres basado en replicación continua, ofreciendo RPO en segundos y RTO en minutos.
5.2. Microsoft Azure
Azure organiza su infraestructura en Regiones y Zonas de Disponibilidad. Sus herramientas para resiliencia incluyen:
HA:
• Azure Load Balancer / Application Gateway: Distribuye el tráfico y proporciona failover a nivel de aplicación.
• Virtual Machine Scale Sets (VMSS): Grupos de máquinas virtuales idénticas con autoescalado y autorreparación.
• Azure SQL Database Geo-replication / Failover Groups: Replicación de bases de datos entre regiones para HA y DR.
DR:
• Azure Backup: Servicio de copia de seguridad para máquinas virtuales, bases de datos y archivos.
• Azure Site Recovery (ASR): Orquestación de DR para máquinas virtuales de Azure, VMware, Hyper-V y servidores físicos, con replicación continua y RTO/RPO bajos.
• Azure Traffic Manager: Balanceador de carga DNS que puede dirigir el tráfico a endpoints saludables en diferentes regiones.
• Azure Storage Geo-redundant Storage (GRS): Replicación de datos de almacenamiento a una región secundaria.
5.3. Google Cloud Platform (GCP)
GCP también utiliza Regiones y Zonas. Sus servicios para construir infraestructuras resilientes incluyen:
HA:
• Google Cloud Load Balancing: Balanceador de carga global que distribuye el tráfico a través de regiones y zonas.
• Managed Instance Groups (MIGs): Grupos de instancias con autoescalado, autorreparación y distribución multi-zona.
• Cloud SQL High Availability: Replicación de bases de datos entre zonas con failover automático.
DR:
• Cloud Storage Geo-redundancy: Replicación de datos de almacenamiento en múltiples regiones.
• Cloud Spanner Multi-Region: Base de datos distribuida globalmente con HA y DR integradas.
• Cloud DNS Failover: Redirecciona el tráfico a recursos alternativos en caso de fallo.
• Google Cloud Backup and DR: Servicio integral de copia de seguridad y recuperación ante desastres para cargas de trabajo críticas.
Tabla Comparativa: Servicios Clave de DR/HA por Proveedor
| Servicio / Característica | AWS | Azure | GCP |
|---|---|---|---|
| Balanceador de Carga | ELB (ALB, NLB, CLB) | Load Balancer, App Gateway, Front Door | Cloud Load Balancing |
| Autoescalado de VMs | Auto Scaling Groups | VM Scale Sets | Managed Instance Groups |
| BD Relacional HA/DR | RDS Multi-AZ, Aurora Global DB | SQL DB Geo-replication, Failover Groups | Cloud SQL HA, Cloud Spanner |
| Servicio DR (RPO/RTO bajos) | AWS Elastic Disaster Recovery (DRS) | Azure Site Recovery (ASR) | Google Cloud Backup and DR |
| Almacenamiento Geo-redundante | S3 CRR, EFS/FSx Multi-AZ | GRS (Storage Accounts) | Cloud Storage Multi-Regional |
| DNS con Failover | Route 53 Failover | Traffic Manager | Cloud DNS Failover |
6. Desafíos Comunes y Soluciones en la Implementación de DR/HA
La implementación de estrategias de DR y HA no está exenta de desafíos. Identificarlos y abordarlos proactivamente es clave para el éxito.
PROBLEMA 01
Costos Elevados de Infraestructura Duplicada
Mantener una infraestructura idéntica o casi idéntica en una región secundaria para DR puede ser extremadamente costoso, especialmente con modelos de «Espera Caliente».
SOLUCIÓN
Optimizar los costos eligiendo la estrategia de DR adecuada para cada carga de trabajo (Piloto Frío o Espera Templada para aplicaciones menos críticas). Utilizar servicios serverless que solo pagan por el uso, y automatizar el escalado a cero de recursos no esenciales en la región de DR.
PROBLEMA 02
Complejidad en la Sincronización de Datos
Asegurar que los datos estén sincronizados entre la región primaria y la de recuperación es un reto, especialmente para bases de datos transaccionales, y puede afectar el RPO.
SOLUCIÓN
Utilizar servicios gestionados de bases de datos con replicación multi-región integrada. Para aplicaciones personalizadas, implementar patrones de replicación asíncrona o síncrona con herramientas como Kafka o Debezium para eventos, o replicación a nivel de almacenamiento.
PROBLEMA 03
Falta de Pruebas de Recuperación ante Desastres
Muchas organizaciones invierten en DR pero fallan en probar sus planes regularmente, lo que lleva a un falso sentido de seguridad.
SOLUCIÓN
Establecer un programa de pruebas de DR periódico, al menos una vez al año. Automatizar las pruebas tanto como sea posible utilizando scripts y herramientas de Infraestructura como Código (IaC). Realizar simulacros de failover y failback para validar RTO/RPO y el proceso de recuperación.
PUNTO CLAVE
La automatización, la elección estratégica de los modelos de DR/HA y las pruebas regulares son pilares para superar los desafíos comunes en la resiliencia cloud.
7. Guía Práctica para Diseñar tu Estrategia de Resiliencia Cloud
Construir una estrategia de DR y HA efectiva requiere un enfoque estructurado. Aquí te presentamos una guía paso a paso:
Paso 1
Evaluar la Criticidad de las Aplicaciones
Clasifica tus aplicaciones y datos en función de su importancia para el negocio. Define RTO y RPO para cada nivel de criticidad. Por ejemplo, una aplicación de comercio electrónico puede requerir un RTO de minutos y un RPO de segundos, mientras que un sistema de informes internos podría tolerar un RTO de horas y un RPO de una hora.
Paso 2
Seleccionar Estrategias de DR y HA
Basándote en los RTO/RPO y el presupuesto, elige las estrategias de DR (Backup, Piloto Frío, Espera Templada, Espera Caliente) y los componentes de HA (Multi-AZ, Load Balancers, Auto Scaling) más adecuados para cada segmento de aplicación.
Paso 3
Diseñar la Arquitectura y Automatizar
Diseña la arquitectura de tu infraestructura resiliente, especificando cómo se implementarán las soluciones de HA y DR. Utiliza herramientas de Infraestructura como Código (IaC) como Terraform o AWS CloudFormation, Azure Resource Manager o Google Cloud Deployment Manager para automatizar el despliegue y la configuración de recursos en ambas regiones (primaria y de recuperación).
EXPLICACIÓN DEL CÓDIGO
Este ejemplo de Terraform crea un grupo de autoescalado de AWS distribuido en dos Zonas de Disponibilidad (AZs), un balanceador de carga de aplicación (ALB) y un grupo objetivo (target group). Esto asegura que la aplicación tenga alta disponibilidad dentro de una región, tolerando fallos de una AZ o de instancias individuales.
resource "aws_vpc" "main" {
cidr_block = "10.0.0.0/16"
}
resource "aws_subnet" "public_a" {
vpc_id = aws_vpc.main.id
cidr_block = "10.0.1.0/24"
availability_zone = "us-east-1a"
}
resource "aws_subnet" "public_b" {
vpc_id = aws_vpc.main.id
cidr_block = "10.0.2.0/24"
availability_zone = "us-east-1b"
}
resource "aws_lb" "app_lb" {
name = "my-app-lb"
internal = false
load_balancer_type = "application"
subnets = [aws_subnet.public_a.id, aws_subnet.public_b.id]
security_groups = [aws_security_group.lb_sg.id]
}
resource "aws_lb_target_group" "app_tg" {
name = "my-app-tg"
port = 80
protocol = "HTTP"
vpc_id = aws_vpc.main.id
}
resource "aws_launch_template" "app_lt" {
name_prefix = "my-app-lt"
image_id = "ami-0abcdef1234567890" # Reemplazar con AMI válida
instance_type = "t3.micro"
user_data = base64encode("#cloud-config\nruncmd:\n - echo 'Hello from ASG!' > /var/www/html/index.html\n - systemctl start httpd") # Ejemplo de script de inicio
key_name = "my-key-pair" # Reemplazar con tu key pair
}
resource "aws_autoscaling_group" "app_asg" {
name = "my-app-asg"
max_size = 4
min_size = 2
desired_capacity = 2
vpc_zone_identifier = [aws_subnet.public_a.id, aws_subnet.public_b.id]
target_group_arns = [aws_lb_target_group.app_tg.arn]
launch_template {
id = aws_launch_template.app_lt.id
version = "$Latest"
}
health_check_type = "ELB"
health_check_grace_period = 300
tag {
key = "Name"
value = "my-app-instance"
propagate_at_launch = true
}
}
resource "aws_security_group" "lb_sg" {
vpc_id = aws_vpc.main.id
ingress {
from_port = 80
to_port = 80
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
}Paso 4
Implementar Monitoreo y Alertas
Configura un monitoreo exhaustivo de la salud de la infraestructura y las aplicaciones en ambas regiones. Establece alertas para detectar fallos rápidamente y notificar a los equipos pertinentes, permitiendo una respuesta rápida ante cualquier incidente. Utiliza servicios como AWS CloudWatch, Azure Monitor o Google Cloud Monitoring.
Paso 5
Realizar Pruebas Regulares de DR
Las pruebas periódicas son vitales para validar la eficacia de tu plan de DR. Simula escenarios de desastre (por ejemplo, el fallo de una AZ o de una región completa) y mide los RTO y RPO reales. Documenta los resultados y ajusta tu estrategia según sea necesario.
Paso 6
Documentar y Capacitar al Equipo
Crea una documentación clara y concisa de tu plan de DR, incluyendo procedimientos de failover y failback. Capacita a tu equipo de operaciones y DevOps para que comprendan sus roles y responsabilidades durante un evento de desastre.
PUNTO CLAVE
Un plan de DR/HA es un documento vivo que requiere evaluación, automatización y pruebas continuas para ser efectivo.

Preguntas Frecuentes
Q. ¿Cuál es la diferencia principal entre RTO y RPO en la recuperación ante desastres?
RTO (Recovery Time Objective) es el tiempo máximo aceptable que una aplicación puede estar inactiva después de un desastre. RPO (Recovery Point Objective) es la cantidad máxima de datos que se puede permitir perder, medida en tiempo desde el momento del desastre.
Q. ¿Qué significa DRaaS y cómo beneficia a las empresas?
DRaaS (Disaster Recovery as a Service) es un servicio de terceros que replica y aloja la infraestructura física o virtual de una organización en la nube. Beneficia a las empresas al reducir la complejidad, los costos de infraestructura y el personal necesario para gestionar un plan de DR interno, ofreciendo RTO y RPO mejorados.
Q. ¿Es posible tener un RTO y RPO de cero en la nube?
Alcanzar un RTO y RPO de cero es extremadamente difícil y costoso, pero las estrategias de «Espera Caliente» (activo-activo multi-región) con replicación síncrona de datos pueden acercarse mucho. Implica una infraestructura completamente duplicada y en ejecución, con failover transparente para el usuario.
Q. ¿Con qué frecuencia debo probar mi plan de Recuperación ante Desastres?
Se recomienda probar el plan de DR al menos una vez al año. Para sistemas de misión crítica, las pruebas pueden ser más frecuentes (trimestrales o semestrales). Además, cualquier cambio significativo en la infraestructura o la aplicación debe ir acompañado de una prueba de DR para validar su impacto.
Conclusión y Perspectivas Futuras
La implementación de estrategias de Recuperación ante Desastres y Alta Disponibilidad en la Nube 2026 es un imperativo para cualquier organización que dependa de la infraestructura cloud. Hemos explorado los fundamentos de DR y HA, las diversas estrategias disponibles, y cómo los principales proveedores de nube (AWS, Azure, GCP) ofrecen herramientas robustas para construir arquitecturas resilientes. La clave del éxito reside en una planificación meticulosa, la automatización a través de IaC, la elección estratégica de los modelos de DR/HA que se alineen con los RTO/RPO y el presupuesto, y, fundamentalmente, las pruebas regulares y la mejora continua.
Mirando hacia el futuro, en 2026 y más allá, la resiliencia cloud continuará evolucionando. Veremos una mayor integración de la inteligencia artificial y el aprendizaje automático para la detección proactiva de anomalías y la orquestación automática de DR. Las arquitecturas serverless y basadas en contenedores seguirán simplificando la implementación de HA y DR, al abstraer gran parte de la gestión de la infraestructura subyacente. La «ingeniería del caos» y las pruebas de resiliencia se volverán prácticas estándar para garantizar que los sistemas puedan soportar fallos inesperados. Adoptar un enfoque proactivo y adaptable es esencial para mantener la continuidad del negocio en un mundo digital en constante cambio.
¡Gracias por leer!
Esperamos que esta guía detallada te haya proporcionado una comprensión clara y práctica para fortalecer la resiliencia de tus aplicaciones en la nube.
¿Preguntas? Déjalas en los comentarios.