RESUMEN
Colas de Mensajes en 2026: Guía para Arquitecturas Escalables con Kafka y RabbitMQ
Explora el poder de las colas de mensajes para construir sistemas backend resilientes y escalables.
Keywords: Kafka, RabbitMQ, Escalabilidad Backend
ÍNDICE
1. Contexto: La Necesidad de Colas de Mensajes en 2026
2. Fundamentos de las Colas de Mensajes
3. Análisis Comparativo: Kafka vs. RabbitMQ
4. Patrones Comunes de Diseño con Colas de Mensajes
5. Resolución de Problemas y Mejores Prácticas
6. Aplicación Práctica: Implementando Colas de Mensajes
7. Casos de Uso Reales y Ejemplos
8. Preguntas Frecuentes (FAQ)
9. Cierre y Perspectivas Futuras
CONTEXTO
La Necesidad de Colas de Mensajes en 2026
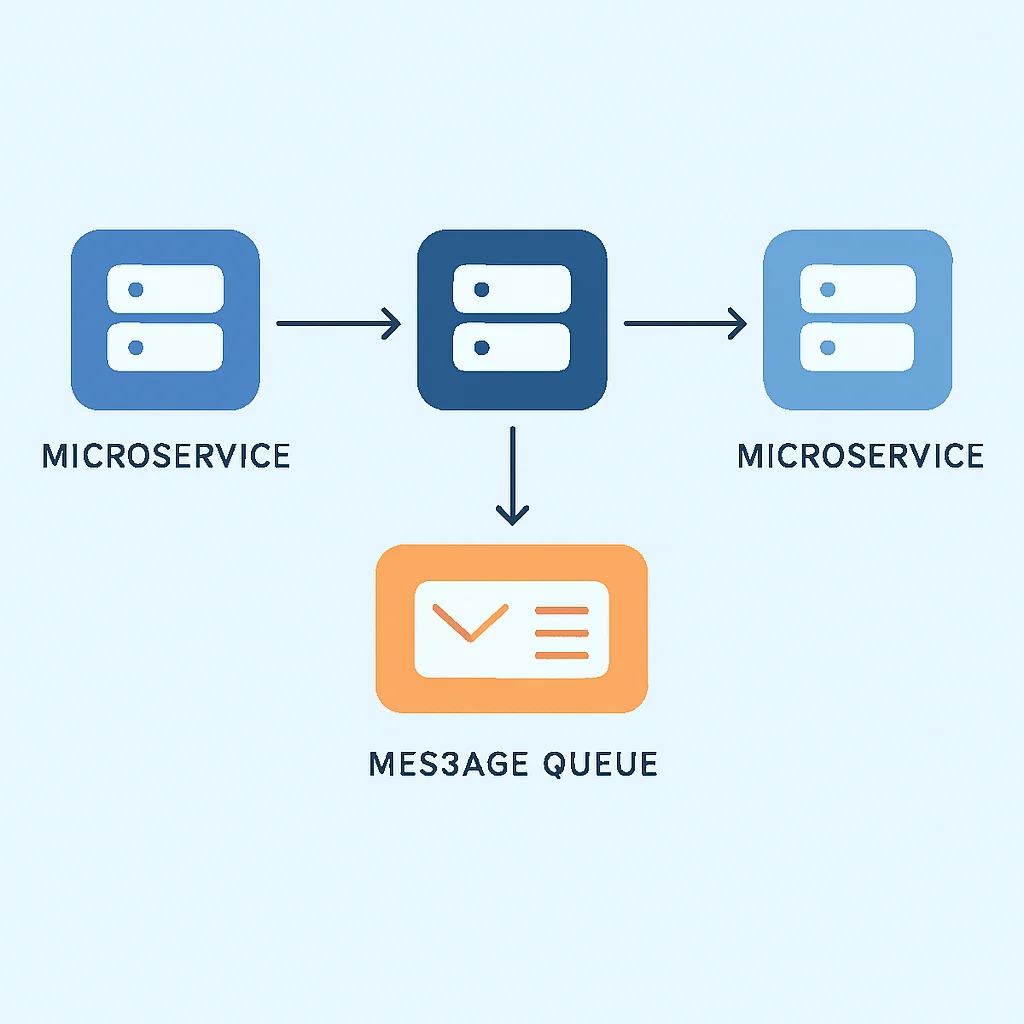
En el panorama tecnológico de 2026, la demanda de sistemas backend altamente escalables, resilientes y con baja latencia es más crítica que nunca. Las arquitecturas monolíticas tradicionales luchan por satisfacer estas exigencias, lo que ha impulsado la adopción masiva de microservicios y sistemas distribuidos. Sin embargo, la comunicación entre estos componentes distribuidos introduce su propio conjunto de complejidades: gestión de fallos, latencia de red, carga desigual y la necesidad de desacoplamiento.
Aquí es donde las colas de mensajes se convierten en un pilar fundamental. Actúan como intermediarios fiables, permitiendo que diferentes partes de una aplicación se comuniquen de forma asíncrona, sin necesidad de estar directamente conectadas o de responder de inmediato. Este desacoplamiento no solo mejora la tolerancia a fallos, ya que un servicio puede fallar sin arrastrar a otros, sino que también facilita la escalabilidad independiente de los componentes.
Consideremos un escenario típico: un servicio de comercio electrónico que procesa pedidos. Cuando un usuario realiza una compra, se desencadenan múltiples operaciones: actualizar el inventario, procesar el pago, enviar una confirmación por correo electrónico, notificar al servicio de envío y registrar la actividad para análisis. Si todas estas operaciones se ejecutan de forma sincrónica, la latencia de la transacción puede ser inaceptablemente alta, y un fallo en cualquiera de estos servicios podría hacer que todo el pedido falle. Con una cola de mensajes, el servicio de pedidos simplemente publica un mensaje «Pedido Realizado» y continúa, dejando que otros servicios consuman ese mensaje y realicen sus tareas de forma independiente y asíncrona.
La integración asíncrona que proporcionan las colas de mensajes es vital para cualquier empresa que busque mantener una ventaja competitiva en 2026, ofreciendo una experiencia de usuario fluida y garantizando la continuidad del negocio frente a cargas impredecibles o fallos parciales del sistema.
FUNDAMENTOS
Fundamentos de las Colas de Mensajes
Una cola de mensajes es un componente de software utilizado para la comunicación entre procesos o entre aplicaciones. Permite que las aplicaciones envíen mensajes a una cola, que luego son almacenados hasta que una aplicación receptora los procesa. Este modelo se basa en el principio de «productor-consumidor», donde un productor envía mensajes y uno o más consumidores los reciben.
Los beneficios clave de usar colas de mensajes incluyen:
Ventajas
✓ Desacoplamiento: Los productores no necesitan conocer la ubicación o el estado de los consumidores, y viceversa. Esto permite que los servicios evolucionen y escalen de forma independiente.
✓ Escalabilidad: Los consumidores pueden ser escalados horizontalmente para manejar picos de carga. Si la carga aumenta, simplemente se añaden más instancias de consumidores para procesar los mensajes más rápido.
✓ Resiliencia: Los mensajes se almacenan persistentemente en la cola hasta que son procesados. Si un consumidor falla, el mensaje no se pierde y puede ser procesado por otro consumidor o por el mismo cuando se recupere.
✓ Gestión de picos de carga: Las colas actúan como un búfer, absorbiendo ráfagas de mensajes y permitiendo que los consumidores los procesen a su propio ritmo, evitando la sobrecarga de los servicios downstream.
✓ Comunicación asíncrona: Los productores no tienen que esperar una respuesta inmediata del consumidor, lo que mejora el rendimiento y la capacidad de respuesta de la aplicación.
PUNTO CLAVE
Las colas de mensajes son fundamentales para construir arquitecturas de microservicios robustas en 2026, proporcionando desacoplamiento, escalabilidad y resiliencia.
Existen dos modelos principales de colas de mensajes:
Modelo Punto a Punto (Point-to-Point)
En este modelo, un mensaje enviado por un productor es consumido por exactamente un consumidor. Una vez que el mensaje es consumido, se elimina de la cola. Este modelo es ideal para tareas que deben ser procesadas una sola vez, como el procesamiento de pagos o la actualización de una base de datos. RabbitMQ es un ejemplo de un sistema que sobresale en este modelo, utilizando colas dedicadas para cada tarea o grupo de tareas.
Modelo Publicador/Suscriptor (Publish/Subscribe)
En este modelo, un mensaje enviado por un publicador puede ser recibido por múltiples suscriptores simultáneamente. El mensaje no se elimina después de ser consumido por un suscriptor, sino que se entrega a todos los suscriptores interesados. Este modelo es perfecto para la difusión de eventos o datos a múltiples servicios que necesitan reaccionar a la misma información, como notificaciones de eventos del sistema o actualizaciones de datos en tiempo real. Kafka es el líder indiscutible en este modelo, diseñado para el procesamiento de streams de datos con alta durabilidad y rendimiento.
ANÁLISIS
Análisis Comparativo: Kafka vs. RabbitMQ
Aunque tanto Apache Kafka como RabbitMQ son soluciones populares para la gestión de colas de mensajes, están diseñados con filosofías y para casos de uso fundamentalmente diferentes. Comprender estas diferencias es crucial para elegir la herramienta adecuada para su arquitectura en 2026.
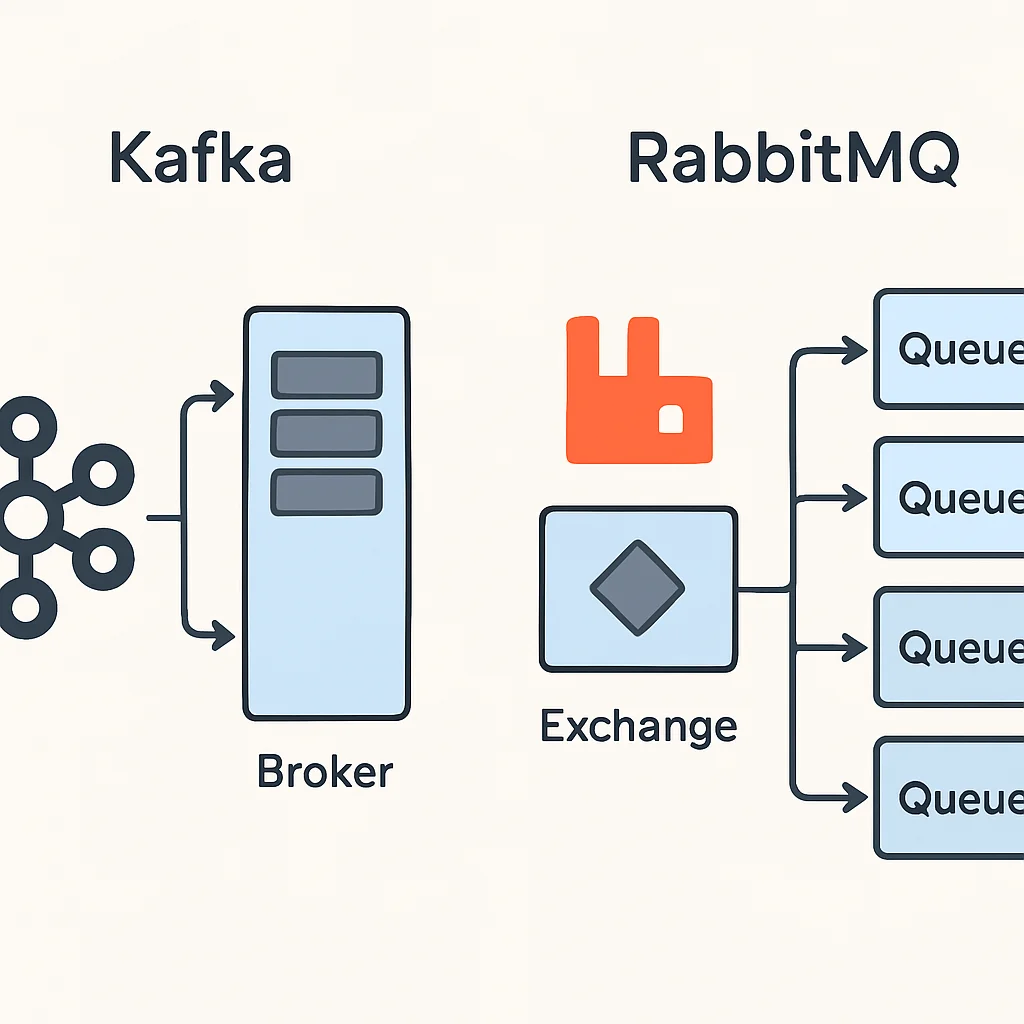
Apache Kafka
Kafka es una plataforma distribuida de streaming de eventos diseñada para manejar flujos de datos en tiempo real con alta capacidad de procesamiento y durabilidad. Fue desarrollado por LinkedIn y donado a la Apache Software Foundation. Sus características principales son:
Características Clave de Kafka
Modelo de Publicación/Suscripción: Los mensajes se organizan en «tópicos» (topics), que son categorías de feeds de mensajes. Los productores publican mensajes en tópicos, y los consumidores se suscriben a tópicos para recibir todos los mensajes publicados en ellos.
Registro Distribuido de Transacciones: Kafka trata los tópicos como un registro de transacciones distribuido, inmutable y particionado. Los mensajes se almacenan en disco y se retienen por un período configurable, lo que permite a los consumidores «reproducir» el historial de eventos.
Alto Rendimiento: Diseñado para manejar millones de mensajes por segundo con baja latencia, ideal para el procesamiento de big data y eventos en tiempo real.
Escalabilidad Horizontal: Los tópicos se dividen en «particiones» que pueden distribuirse entre múltiples brokers (servidores Kafka). Los productores escriben en particiones y los consumidores leen desde ellas en paralelo, permitiendo una escalabilidad casi lineal.
Durabilidad y Tolerancia a Fallos: Los mensajes se replican a través de múltiples brokers, asegurando que los datos no se pierdan incluso si un broker falla. Utiliza Apache ZooKeeper (o Kafka Raft – KRaft en versiones más recientes) para la gestión del clúster.
RabbitMQ
RabbitMQ es un broker de mensajes de código abierto que implementa el estándar Advanced Message Queuing Protocol (AMQP). Es conocido por su flexibilidad en el enrutamiento de mensajes y su capacidad para manejar una variedad de patrones de mensajería. Sus características principales son:
Características Clave de RabbitMQ
Modelo Flexible de Enrutamiento: RabbitMQ utiliza «exchanges» que reciben mensajes de productores y los enrutan a «colas» basándose en reglas definidas (bindings). Admite varios tipos de exchanges (direct, topic, fanout, headers) para diferentes patrones de enrutamiento.
Modelo Punto a Punto y Publicación/Suscripción: Aunque su punto fuerte es el enrutamiento complejo, puede simular ambos modelos. Es excelente para escenarios donde los mensajes deben ser procesados por un único consumidor o en patrones de work queues.
Entrega Fiable: Ofrece garantías de entrega de mensajes (at-least-once, at-most-once) y confirmaciones de mensajes (acknowledgements) para asegurar que los mensajes no se pierdan.
Fácil de Usar y Configurar: Generalmente, es más sencillo de configurar y operar para casos de uso básicos y moderados en comparación con Kafka.
Plugin Extensible: Ofrece una amplia gama de plugins para características adicionales como gestión de colas de mensajes no entregados (Dead-Letter Queues), sharding, y más.
Tabla Comparativa: Kafka vs. RabbitMQ
| Característica | Apache Kafka | RabbitMQ |
|---|---|---|
| Filosofía Principal | Plataforma de streaming de eventos, registro distribuido. | Broker de mensajes de propósito general, cola de mensajes tradicional. |
| Modelo de Mensajería | Publicación/Suscripción (tópicos, particiones). | Punto a Punto y Publicación/Suscripción (exchanges, colas, bindings). |
| Orden de Mensajes | Garantizado por partición. | Garantizado por cola. |
| Persistencia | Alta, los mensajes se retienen en disco por un tiempo configurable. | Configurable, se eliminan después de ser consumidos (o según TTL). |
| Rendimiento | Muy alto throughput, baja latencia para grandes volúmenes. | Buen throughput, mayor latencia para volúmenes muy altos. |
| Escalabilidad | Excelente escalabilidad horizontal a través de particiones y grupos de consumidores. | Buena escalabilidad horizontal con clústeres, pero limitada por el enfoque de cola. |
| Complejidad Operativa | Más compleja de configurar y operar, especialmente con Zookeeper/KRaft. | Relativamente más simple de configurar y operar. |
| Casos de Uso Típicos | Procesamiento de eventos en tiempo real, big data, logs, CDC, métricas. | Distribución de tareas, microservicios, notificaciones, colas de trabajo. |
PUNTO CLAVE
La elección entre Kafka y RabbitMQ depende de la necesidad: Kafka para streaming de datos de alto volumen y durabilidad a largo plazo; RabbitMQ para enrutamiento complejo y colas de trabajo con garantías de entrega.
PATRONES DE DISEÑO
Patrones Comunes de Diseño con Colas de Mensajes
La implementación de colas de mensajes no se limita a simplemente enviar y recibir datos. Existen patrones de diseño bien establecidos que maximizan los beneficios de estas tecnologías en arquitecturas distribuidas.
1. Colas de Trabajo (Work Queues)
Este es el patrón más básico, donde un productor envía tareas a una cola, y múltiples consumidores compiten para procesar esas tareas. Cada tarea es procesada por un único consumidor. Es ideal para distribuir cargas de trabajo pesadas o de larga duración. RabbitMQ es excelente para este patrón.
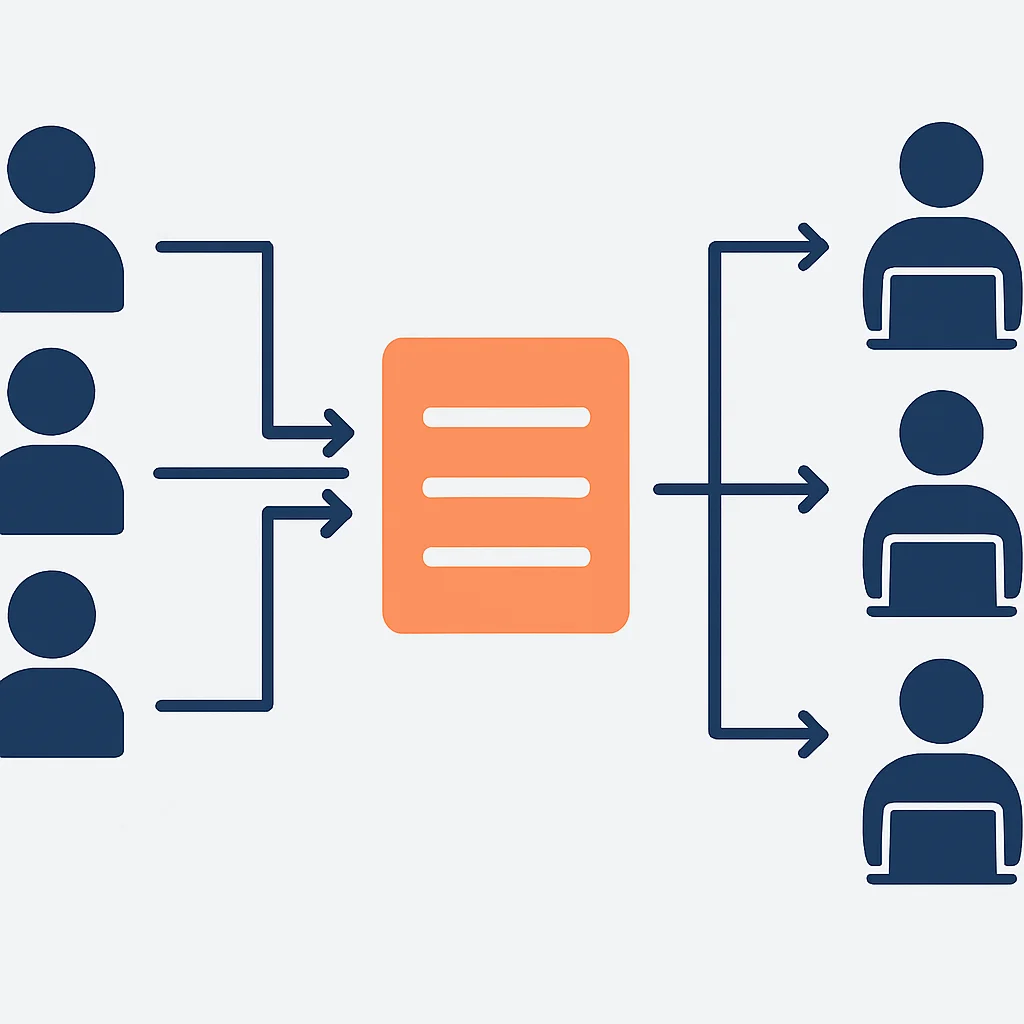
2. Publicación/Suscripción (Publish/Subscribe)
Como se mencionó, este patrón permite que un mensaje sea entregado a múltiples consumidores. Un publicador envía un mensaje a un «tópico» o «exchange», y todos los suscriptores interesados en ese tópico/exchange reciben una copia del mensaje. Kafka es el rey de este patrón, pero RabbitMQ también lo soporta con exchanges de tipo fanout o topic.
3. Patrón Saga
En microservicios, las transacciones que abarcan múltiples servicios son un desafío. El patrón Saga es una forma de gestionar transacciones distribuidas, donde una secuencia de transacciones locales se ejecuta y se compensa si alguna falla. Las colas de mensajes se utilizan para coordinar la comunicación entre los servicios, enviando eventos que desencadenan la siguiente transacción o una transacción de compensación. Esto es crucial para mantener la consistencia de los datos en sistemas distribuidos.
PUNTO CLAVE
El patrón Saga, facilitado por colas de mensajes, es esencial para gestionar la consistencia de datos en transacciones distribuidas complejas en arquitecturas de microservicios modernas.
4. Event Sourcing y CQRS
Event Sourcing: En lugar de almacenar el estado actual de una entidad, se almacenan todos los eventos que han ocurrido a esa entidad en una secuencia inmutable (un log de eventos, como un tópico de Kafka). El estado actual se reconstruye reproduciendo estos eventos. Las colas de mensajes (especialmente Kafka) son ideales para implementar el log de eventos.
CQRS (Command Query Responsibility Segregation): Separa los modelos de lectura y escritura. Los comandos (escrituras) se procesan a través de un modelo, y los eventos resultantes se publican en una cola de mensajes. Los modelos de consulta (lecturas) se actualizan escuchando estos eventos. Esto permite optimizar cada modelo de forma independiente.
RESOLUCIÓN DE PROBLEMAS
Resolución de Problemas y Mejores Prácticas
La implementación de colas de mensajes introduce desafíos específicos que deben abordarse para garantizar la fiabilidad y el rendimiento del sistema.
PROBLEMA 01
Garantizar el Orden de los Mensajes
En sistemas distribuidos, el orden de los mensajes puede ser crítico (ej., un evento de «crear usuario» debe preceder a un evento de «actualizar usuario»). Sin embargo, la naturaleza asíncrona de las colas puede llevar a que los mensajes se procesen fuera de orden si no se gestiona correctamente.
SOLUCIÓN — Estrategias de Ordenamiento
Kafka: Garantiza el orden de los mensajes dentro de una partición. Para mantener el orden de mensajes relacionados, asegúrese de que todos los mensajes para una entidad específica (ej. un userId) se envíen a la misma partición utilizando una clave de partición consistente (ej. userId).
RabbitMQ: El orden se mantiene dentro de una cola. Para garantizar el orden, un solo consumidor debe procesar una cola o, si hay múltiples consumidores, deben coordinarse para procesar mensajes de forma ordenada, lo cual es más complejo y generalmente se evita para un orden estricto.
En ambos casos, para el orden global, a menudo se requiere un punto de cuello de botella o un mecanismo de reordenamiento en el consumidor, lo cual puede impactar la escalabilidad.
PROBLEMA 02
Idempotencia del Consumidor
Debido a la naturaleza distribuida y a los reintentos (retry mechanisms), un mensaje puede ser entregado y procesado más de una vez (garantía «at-least-once»). Si la operación del consumidor no es idempotente (es decir, producir el mismo resultado si se ejecuta varias veces), esto puede llevar a inconsistencias de datos (ej., duplicar un pedido o un cobro).
SOLUCIÓN — Diseño de Consumidores Idempotentes
Diseñe sus consumidores para que sus operaciones sean idempotentes. Esto se puede lograr de varias maneras:
- Claves Únicas: Incluya un identificador único (ID de mensaje o ID de transacción) en cada mensaje. Al procesar, verifique si este ID ya ha sido procesado. Si es así, ignore el mensaje duplicado.
- Operaciones Idempotentes: Use operaciones de base de datos que sean inherentemente idempotentes (ej.,
UPSERTen lugar deINSERTsi el ID ya existe). - Guarda de Estado: Mantenga un registro del último ID de mensaje procesado para cada consumidor o partición.
La idempotencia es una de las mejores prácticas más importantes para garantizar la consistencia en sistemas distribuidos asíncronos.