
Estrategias de Caching para Alto Rendimiento en 2026
Optimiza el rendimiento y la escalabilidad de tus aplicaciones backend con técnicas de caching avanzadas.
Keywords: Caching, Redis, Memcached
INTRODUCCIÓN
Dominando el Caching: La Clave para Backends Escalables en 2026
En el dinámico mundo del desarrollo de software, la velocidad y la eficiencia son más que un simple plus; son un requisito fundamental. A medida que las aplicaciones web y móviles crecen en complejidad y volumen de usuarios, los sistemas backend se enfrentan a desafíos cada vez mayores para entregar datos de manera rápida y confiable. Aquí es donde el caching emerge como una estrategia indispensable. En 2026, con la proliferación de la computación en la nube, los microservicios y las aplicaciones en tiempo real, una estrategia de caching bien implementada puede ser la diferencia entre una aplicación exitosa y una que lucha por mantenerse a flote.
Este informe de análisis profundiza en las estrategias de caching más efectivas para sistemas backend, examinando las soluciones líderes como Redis y Memcached, y proporcionando una guía práctica para su implementación. Nuestro objetivo en Kwonsejo es equiparte con el conocimiento y las herramientas necesarias para optimizar el rendimiento y la escalabilidad de tus aplicaciones, asegurando que tus sistemas estén preparados para las demandas del futuro.
ÍNDICE
1. ¿Por Qué el Caching es Crucial en 2026?
2. Tipos de Estrategias de Caching
3. Comparativa de Soluciones de Caching: Redis vs. Memcached
4. Implementación de Caching con Redis
5. Implementación de Caching con Memcached
6. Estrategias Avanzadas y Consideraciones
7. Casos de Uso y Ejemplos del Mundo Real
8. El Futuro del Caching: Tendencias para 2026 y Más Allá
9. Preguntas Frecuentes
FUNDAMENTOS
¿Por Qué el Caching es Crucial en 2026?
En la actualidad, las expectativas de los usuarios son más altas que nunca. Un sitio web o una aplicación lenta no solo frustra a los usuarios, sino que también puede traducirse en una pérdida significativa de ingresos y reputación. En 2026, con la infraestructura de la nube omnipresente y la proliferación de dispositivos conectados, la capacidad de servir contenido rápidamente es un factor crítico de éxito. El caching aborda este desafío almacenando copias de datos de acceso frecuente en ubicaciones de almacenamiento más rápidas, más cercanas al consumidor o con menor latencia.
Beneficios Tangibles del Caching
Los beneficios de implementar una estrategia de caching robusta son múltiples y se extienden a lo largo de toda la arquitectura de una aplicación:
1. Reducción de la Latencia: Almacenar datos en caché reduce drásticamente el tiempo necesario para recuperarlos. Por ejemplo, una consulta a una base de datos compleja que podría tardar 200 milisegundos puede reducirse a 5-10 milisegundos si los datos se sirven desde una caché en memoria. Esto se traduce directamente en una experiencia de usuario más fluida y receptiva.
2. Disminución de la Carga de la Base de Datos: Las bases de datos suelen ser el cuello de botella más común en muchas aplicaciones. Al servir la mayoría de las solicitudes de lectura desde la caché, se reduce significativamente la presión sobre la base de datos, lo que le permite manejar operaciones de escritura y consultas más complejas de manera eficiente. Esto prolonga la vida útil del hardware de la base de datos y reduce la necesidad de escalar verticalmente tan rápidamente.
3. Mejora de la Escalabilidad: El caching permite que un sistema maneje un mayor volumen de solicitudes sin necesidad de añadir más recursos de backend (servidores de aplicación o bases de datos). Al desacoplar las lecturas de la base de datos, se puede escalar horizontalmente la capa de aplicación sin sobrecargar la capa de datos. Un buen sistema de caching puede permitir que una aplicación maneje un 50-80% más de tráfico con los mismos recursos de backend.
4. Reducción de Costos Operacionales: Menos carga en la base de datos y en los servidores de aplicación significa menos recursos de computación y almacenamiento necesarios. En entornos de nube, esto se traduce directamente en ahorros significativos en las facturas mensuales. Un estudio reciente estimó que una estrategia de caching efectiva puede reducir los costos de infraestructura en un 15-30% para aplicaciones con alto tráfico.
5. Mayor Tolerancia a Fallos: Si la base de datos experimenta una interrupción temporal, el sistema de caché puede seguir sirviendo datos obsoletos (pero aún útiles) durante un período, proporcionando una capa de resiliencia y evitando una interrupción completa del servicio.
PUNTO CLAVE
En 2026, el caching no es un lujo, sino una necesidad operativa. Es la base para construir aplicaciones backend que sean rápidas, escalables, rentables y resistentes frente a las crecientes demandas de los usuarios y el tráfico web.
ESTRATEGIAS
Tipos de Estrategias de Caching
El caching no es una solución única, sino un conjunto de técnicas que se pueden aplicar en diferentes niveles de la pila tecnológica de una aplicación. Comprender los distintos tipos de caching es fundamental para diseñar una estrategia integral y eficiente.
Capas de Caching Comunes
Desde el navegador del usuario hasta la base de datos, cada capa puede beneficiarse del caching:
1. Caching a Nivel de Navegador/Cliente
Descripción — El navegador web almacena recursos estáticos (imágenes, CSS, JavaScript) después de la primera carga. Utiliza encabezados HTTP como Cache-Control y Expires.
Beneficio — Reduce la carga del servidor y mejora drásticamente los tiempos de carga para visitas repetidas. Ideal para activos que no cambian con frecuencia.
2. Caching a Nivel de CDN (Content Delivery Network)
Descripción — Las CDN almacenan copias de contenido estático (e incluso dinámico en algunos casos) en servidores distribuidos geográficamente (puntos de presencia o PoPs). Cuando un usuario solicita contenido, se sirve desde el PoP más cercano.
Beneficio — Reduce la latencia al acercar el contenido al usuario final, disminuye la carga del servidor de origen y mejora la resistencia frente a picos de tráfico. Esencial para aplicaciones globales.
3. Caching a Nivel de DNS
Descripción — Los resolvedores DNS almacenan registros de nombres de dominio a direcciones IP. Esto evita la necesidad de realizar una nueva consulta DNS cada vez que un usuario intenta acceder a un dominio.
Beneficio — Acelera la resolución de nombres de dominio, contribuyendo a un inicio más rápido de la conexión.
4. Caching a Nivel de Aplicación/Backend
Descripción — Almacena los resultados de operaciones costosas (consultas a bases de datos, cálculos complejos, llamadas a APIs externas) en memoria o en un almacén de datos rápido. Aquí es donde Redis y Memcached brillan.
Beneficio — Reduce la carga sobre las bases de datos y servicios externos, minimiza el tiempo de procesamiento en los servidores de aplicación y mejora la escalabilidad del backend. Es el foco principal de este artículo.
5. Caching a Nivel de Base de Datos
Descripción — Muchas bases de datos (como PostgreSQL, MySQL) tienen sus propios mecanismos de caching internos para consultas frecuentes, índices o bloques de datos. ORMs también pueden implementar caching de resultados.
Beneficio — Acelera el acceso a datos dentro de la propia base de datos, aunque no exime a la aplicación de la necesidad de su propia capa de caching.
COMPARATIVA
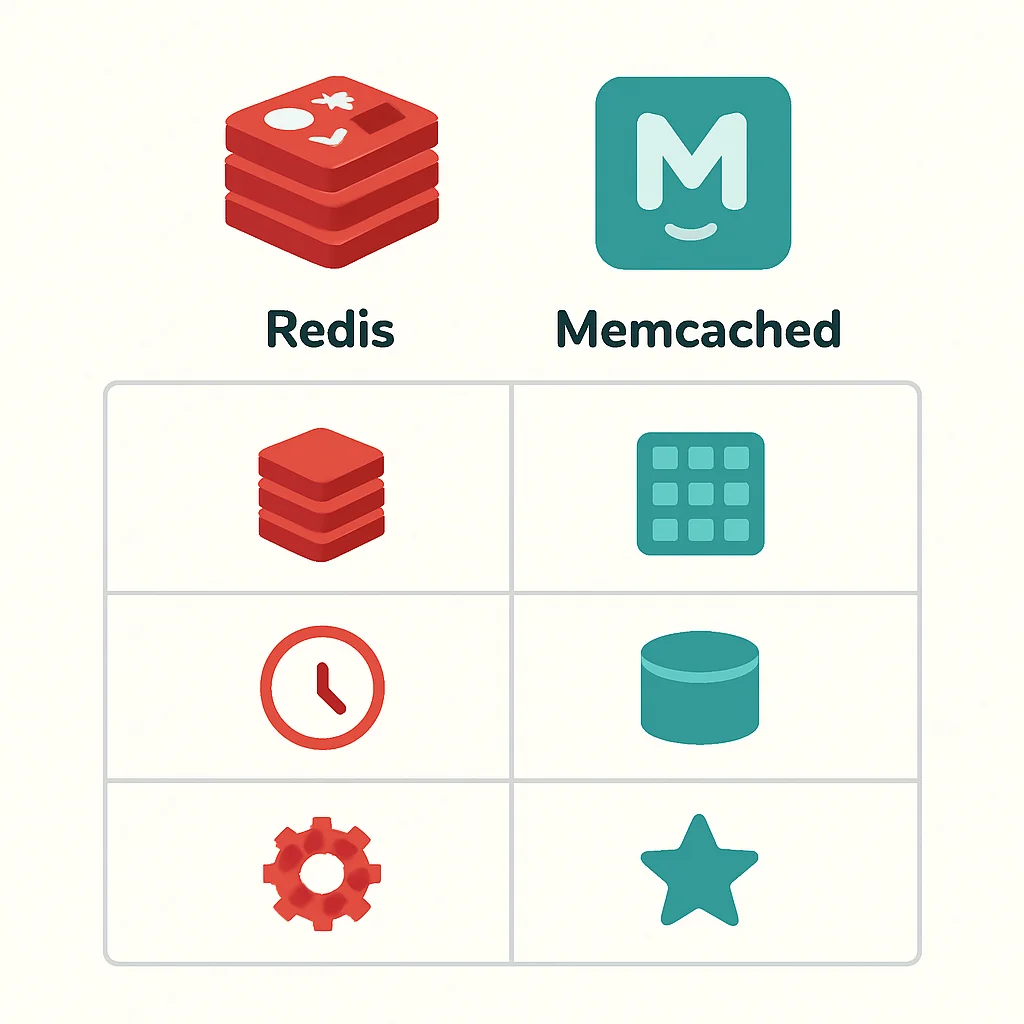
Comparativa de Soluciones de Caching: Redis vs. Memcached
Cuando se habla de caching a nivel de aplicación, dos nombres dominan el panorama: Redis y Memcached. Ambos son almacenes de datos en memoria de código abierto, pero ofrecen funcionalidades y enfoques distintos. La elección entre uno y otro depende en gran medida de los requisitos específicos de tu aplicación.
Memcached: El Almacén Simple y Rápido
Memcached es un sistema de caché de objetos distribuido de alto rendimiento, diseñado para acelerar aplicaciones web dinámicas reduciendo la carga de la base de datos. Su fortaleza reside en su simplicidad: es un almacén de clave-valor puro, in-memory, que soporta la mayoría de los lenguajes de programación. Es ideal para caching de objetos simples, como resultados de consultas SQL o fragmentos de HTML, donde la persistencia de los datos no es crítica.
Ventajas:
✓ Simplicidad: Fácil de configurar y usar, con una API muy sencilla.
✓ Alto Rendimiento: Excelente para operaciones de lectura/escritura rápidas de datos simples.
✓ Distribución: Diseñado para escalar horizontalmente a través de múltiples servidores.
✓ Multihilo: Puede aprovechar múltiples núcleos de CPU para un mejor rendimiento.
Redis: El Almacén de Estructuras de Datos Versátil
Redis (Remote Dictionary Server) es mucho más que una simple caché. Es un almacén de estructuras de datos en memoria, que puede ser usado como base de datos, caché y bróker de mensajes. Soporta una amplia variedad de tipos de datos, como cadenas, hashes, listas, conjuntos, conjuntos ordenados, bitmaps e hyperloglogs. Redis ofrece persistencia opcional, replicación, clustering y funcionalidades más avanzadas como transacciones, pub/sub y scripts Lua.
Ventajas:
✓ Versatilidad: Soporta estructuras de datos complejas, lo que permite casos de uso más allá del simple caching.
✓ Persistencia: Puede guardar datos en disco, lo que lo hace adecuado para almacenar datos críticos que necesitan sobrevivir a reinicios.
✓ Replicación y Alta Disponibilidad: Permite configuraciones master-replica para redundancia y escalabilidad de lectura.
✓ Funcionalidades Avanzadas: Pub/sub, transacciones, Lua scripting, geolocalización, streams.
✓ Comunidad Activa: Gran soporte y desarrollo continuo.
Tabla Comparativa: Redis vs. Memcached
Aquí una tabla que resume las principales diferencias para ayudarte a tomar una decisión informada:
PUNTO CLAVE
Si necesitas un almacén de clave-valor rápido y sencillo para datos no críticos, Memcached es una excelente opción. Si tu aplicación requiere estructuras de datos más complejas, persistencia, alta disponibilidad, o funcionalidades de mensajería, Redis es la elección superior.
IMPLEMENTACIÓN
Implementación de Caching con Redis
Redis es una herramienta increíblemente potente y flexible para el caching. Aquí te mostramos cómo puedes integrarlo en una aplicación backend utilizando Python, un lenguaje común en el desarrollo de microservicios y APIs.
Configuración Básica de Redis
Primero, asegúrate de tener un servidor Redis en ejecución. Puedes instalarlo localmente o usar un servicio gestionado como AWS ElastiCache, Google Cloud Memorystore o Azure Cache for Redis. Para Python, la biblioteca cliente más popular es redis-py.
EXPLICACIÓN DEL CÓDIGO
Este bloque de código muestra cómo instalar la biblioteca redis-py y establecer una conexión básica con un servidor Redis, utilizando la configuración por defecto (localhost, puerto 6379).
# Instalación de la librería
pip install redis
# Ejemplo de conexión en Python
import redis
# Conectarse a una instancia local de Redis
# Si Redis está en otro host o puerto, ajusta los parámetros
r = redis.Redis(host='localhost', port=6379, db=0)
try:
r.ping()
print("Conexión a Redis establecida exitosamente!")
except redis.exceptions.ConnectionError as e:
print(f"Error al conectar a Redis: {e}")
Patrones de Caching Comunes con Redis
El patrón de caching más común es el «Cache-Aside» (o «Lazy Loading»), donde la aplicación es responsable de comprobar la caché antes de consultar la base de datos.
EXPLICACIÓN DEL CÓDIGO
Este ejemplo simula la obtención de datos de un usuario. Primero intenta recuperarlos de Redis. Si no están en caché, los obtiene de una base de datos simulada (simulando una operación costosa), los almacena en Redis con un tiempo de expiración (TTL) de 3600 segundos (1 hora) y luego los devuelve. Esto reduce la carga de la base de datos para solicitudes repetidas del mismo usuario.
import redis
import json
import time
r = redis.Redis(host='localhost', port=6379, db=0)
# Simulación de una base de datos lenta
def get_user_from_db(user_id):
print(f"Obteniendo usuario {user_id} de la base de datos...")
time.sleep(2) # Simula una operación lenta de DB
if user_id == "user:123":
return {"id": "123", "name": "Alice Smith", "email": "[email protected]"}
return None
def get_user_data(user_id):
cache_key = f"user_data:{user_id}"
# 1. Intentar obtener de la caché
cached_data = r.get(cache_key)
if cached_data:
print(f"Datos de usuario {user_id} obtenidos de la caché.")
return json.loads(cached_data)
# 2. Si no está en caché, obtener de la DB
user_data = get_user_from_db(user_id)
if user_data:
# 3. Almacenar en caché con un TTL (Time To Live) de 1 hora
r.setex(cache_key, 3600, json.dumps(user_data))
print(f"Datos de usuario {user_id} almacenados en caché.")
return user_data
# Primera llamada (irá a la DB y luego a la caché)
user1 = get_user_data("user:123")
print(f"Usuario: {user1}\n")
# Segunda llamada (irá directamente a la caché)
user2 = get_user_data("user:123")
print(f"Usuario: {user2}\n")
# Intentar obtener un usuario que no existe
user3 = get_user_data("user:456")
print(f"Usuario: {user3}\n")
Manejo de Problemas: Cache Stampede
Un problema común en el caching es el «Cache Stampede» (también conocido como «Dog-piling»). Ocurre cuando un elemento de la caché expira, y múltiples solicitudes intentan acceder a ese elemento casi simultáneamente. Todas ven que el elemento no está en caché y proceden a consultar la base de datos o el servicio de origen, lo que puede sobrecargar el backend.
PROBLEMA 01
Cache Stampede por Expiración Simultánea
Cuando un elemento popular de la caché expira y cientos o miles de usuarios lo solicitan al mismo tiempo, todas las solicitudes pasan directamente a la base de datos, causando una sobrecarga masiva y una posible caída del servicio.
SOLUCIÓN — Implementar un Bloqueo de Caché
Una solución es usar un bloqueo distribuido (con Redis) para asegurar que solo una solicitud regenere el valor de la caché, mientras que las demás esperan pasivamente. Otra estrategia es la «expiración temprana probabilística», donde la caché se actualiza antes de su expiración real para evitar el efecto estampida.
EXPLICACIÓN DEL CÓDIGO
Este fragmento de código ilustra cómo se puede usar SETNX (SET if Not eXists) de Redis para implementar un bloqueo simple. La primera solicitud que intenta establecer el bloqueo lo consigue y regenera la caché. Las demás solicitudes esperan hasta que el bloqueo se libera y el valor de la caché está disponible.
import redis
import json
import time
r = redis.Redis(host='localhost', port=6379, db=0)
# Simulación de una base de datos lenta
def get_user_from_db_slow(user_id):
print(f"🔴 Obteniendo usuario {user_id} de la base de datos (lento)...")
time.sleep(3) # Simula una operación muy lenta
return {"id": user_id.split(':')[1], "name": "Bob", "email": f"bob{user_id.split(':')[1]}@example.com"}
def get_user_data_with_lock(user_id):
cache_key = f"user_data:{user_id}"
lock_key = f"lock:{cache_key}"
lock_timeout = 10 # segundos para que expire el bloqueo
cached_data = r.get(cache_key)
if cached_data:
print(f"✅ Datos de usuario {user_id} obtenidos de la caché.")
return json.loads(cached_data)
# Si no está en caché, intentar adquirir el bloqueo
if r.setnx(lock_key, "1"): # setnx devuelve 1 si se establece, 0 si ya existe
r.expire(lock_key, lock_timeout) # Establecer un TTL para el bloqueo
print(f"🔒 Bloqueo adquirido para {user_id}. Regenerando caché...")
try:
user_data = get_user_from_db_slow(user_id)
if user_data:
r.setex(cache_key, 3600, json.dumps(user_data))
print(f"📜 Datos de usuario {user_id} almacenados en caché y bloqueo liberado.")
return user_data
finally:
r.delete(lock_key) # Asegurarse de liberar el bloqueo
else:
# Si no se pudo adquirir el bloqueo, esperar un poco e intentar de nuevo
print(f"🔐 Esperando por el bloqueo de {user_id}...")
time.sleep(0.5) # Esperar un corto período
return get_user_data_with_lock(user_id) # Reintentar
# Simulación de múltiples solicitudes concurrentes
import threading
def request_user(user_id):
data = get_user_data_with_lock(user_id)
# print(f"Solicitud para {user_id} completada.")
threads = []
for _ in range(5): # 5 solicitudes concurrentes para el mismo usuario
t = threading.Thread(target=request_user, args=("user:456",))
threads.append(t)
t.start()
for t in threads:
t.join()
print("\nTodas las solicitudes concurrentes han terminado.")
IMPLEMENTACIÓN
Implementación de Caching con Memcached
Memcached, aunque más simple que Redis, es extremadamente eficiente para su propósito principal: almacenar objetos pequeños y volátiles en memoria. Es ideal para casos de uso donde la velocidad pura y la baja sobrecarga son primordiales, y la persistencia de datos no es una preocupación.
Configuración Básica de Memcached
Al igual que con Redis, necesitarás un servidor Memcached en ejecución. Para Python, la biblioteca python-memcached es una opción popular.
EXPLICACIÓN DEL CÓDIGO
Este código muestra cómo instalar python-memcached y conectarse a un servidor Memcached. Luego, demuestra las operaciones básicas de set (establecer), get (obtener) y delete (eliminar) un valor, incluyendo un tiempo de expiración.
# Instalación de la librería
pip install python-memcached
# Ejemplo de conexión y uso básico en Python
import memcache
import time
# Conectarse a una instancia local de Memcached
# El puerto por defecto es 11211
mc = memcache.Client(['127.0.0.1:11211'], debug=0)
# Establecer un valor en caché con un TTL de 60 segundos
mc.set("my_key", "Hello, Memcached!", time=60)
print("Valor 'my_key' establecido en caché.")
# Obtener el valor de la caché
value = mc.get("my_key")
print(f"Valor obtenido de la caché: {value}")
# Esperar para que el valor expire (o casi)
print("Esperando 65 segundos para la expiración...")
time.sleep(65)
# Intentar obtener el valor de nuevo después de la expiración
value_after_expire = mc.get("my_key")
print(f"Valor obtenido después de la expiración: {value_after_expire}") # Será None
# Establecer un nuevo valor y luego eliminarlo
mc.set("another_key", "This will be deleted.")
print(f"Valor 'another_key' establecido: {mc.get('another_key')}")
mc.delete("another_key")
print(f"Valor 'another_key' después de eliminar: {mc.get('another_key')}")
Integración de Memcached en una Aplicación Web
Memcached es frecuentemente utilizado para:
● Caching de resultados de consultas: Almacenar el resultado de una consulta de base de datos costosa.
● Caching de fragmentos HTML: Guardar partes de páginas web generadas dinámicamente.
● Sesiones de usuario: Almacenar datos de sesión para una aplicación web distribuida.
EXPLICACIÓN DEL CÓDIGO
Este ejemplo simula una función que obtiene un artículo de noticias. Si el artículo está en Memcached, lo devuelve rápidamente. Si no, lo «carga» de una fuente lenta (simulada) y lo guarda en Memcached para futuras solicitudes, con un TTL de 5 minutos.
import memcache
import time
import json
mc = memcache.Client(['127.0.0.1:11211'], debug=0)
# Simulación de una función que obtiene datos de un servicio lento
def get_article_from_external_service(article_id):
print(f"🔴 Obteniendo artículo {article_id} de servicio externo (lento)...")
time.sleep(1.5) # Simula latencia
return {"id": article_id, "title": f"Noticia Impactante {article_id}", "content": "Contenido muy interesante...", "author": "Kwonsejo"}
def get_news_article(article_id):
cache_key = f"news_article:{article_id}"
# 1. Intentar obtener de la caché
cached_article = mc.get(cache_key)
if cached_article:
print(f"✅ Artículo {article_id} obtenido de la caché.")
return json.loads(cached_article) # Memcached almacena strings, deserializar
# 2. Si no está en caché, obtener del servicio externo
article_data = get_article_from_external_service(article_id)
if article_data:
# 3. Almacenar en caché con un TTL de 5 minutos (300 segundos)
# Los objetos deben serializarse a string antes de almacenarse en Memcached
mc.set(cache_key, json.dumps(article_data), time=300)
print(f"📜 Artículo {article_id} almacenado en caché.")
return article_data
# Primera solicitud
article1 = get_news_article("abc-101")
print(f"Artículo: {article1['title']}\n")
# Segunda solicitud (debería ser instantánea)
article2 = get_news_article("abc-101")
print(f"Artículo: {article2['title']}\n")
# Solicitud de un nuevo artículo
article3 = get_news_article("xyz-202")
print(f"Artículo: {article3['title']}\n")
PUNTO CLAVE
Memcached es el campeón de la simplicidad y la velocidad para el caching de clave-valor. Es excelente para aliviar la carga de la base de datos para datos volátiles y de acceso frecuente, pero carece de la riqueza de estructuras de datos y funcionalidades avanzadas que ofrece Redis.
AVANZADO
Estrategias Avanzadas y Consideraciones
Una vez que se dominan los fundamentos del caching, es crucial explorar estrategias más sofisticadas para manejar escenarios complejos, asegurar la consistencia de los datos y optimizar aún más el rendimiento.
Invalidación de Caché: El Problema Más Difícil
La invalidación de caché es uno de los desafíos más complejos en el diseño de sistemas distribuidos. El objetivo es asegurar que los usuarios siempre vean la información más actualizada sin comprometer los beneficios del caching.
ADVERTENCIA
«Hay dos cosas difíciles en la informática: la invalidación de caché y la denominación de cosas.» Esta famosa cita subraya la dificultad de mantener la coherencia entre la caché y la fuente de datos original. Una invalidación mal manejada puede llevar a que los usuarios vean datos obsoletos, lo que afecta la experiencia y la confianza.
Métodos de invalidación:
● TTL (Time To Live): El método más simple. Los datos expiran automáticamente después de un período. Adecuado para datos que pueden ser ligeramente obsoletos.
● Basado en Eventos: Cuando los datos de origen cambian (ej. una actualización en la base de datos), se envía un evento que invalida la entrada correspondiente en la caché. Esto se puede lograr con sistemas de mensajería (ej. Kafka, RabbitMQ) o Pub/Sub de Redis.
● LRU (Least Recently Used) / LFU (Least Frequently Used): Políticas de expulsión cuando la caché se llena. No es una invalidación proactiva, sino una gestión del espacio.
● Versiones: Incluir un número de versión en la clave de caché. Cuando los datos cambian, se incrementa la versión, lo que hace que las claves de caché antiguas sean «inválidas».
Patrones de Escritura en Caché
Mientras que el patrón «Cache-Aside» es para lecturas, existen patrones específicos para manejar las escrituras y mantener la coherencia.
Ventajas y Desventajas de Patrones de Escritura
✓ Write-Through: La aplicación escribe datos tanto en la caché como en la base de datos simultáneamente. Garantiza que la caché siempre tenga los datos más recientes.
Ventaja: Consistencia inmediata. Desventaja: Mayor latencia de escritura.
✓ Write-Back (Write-Behind): La aplicación escribe datos solo en la caché, y la caché los escribe en la base de datos de forma asíncrona.
Ventaja: Muy baja latencia de escritura. Desventaja: Riesgo de pérdida de datos si la caché falla antes de la escritura en DB.
✓ Write-Around: La aplicación escribe directamente en la base de datos, omitiendo la caché. La caché solo se actualiza en lecturas posteriores (lazy loading).
Ventaja: Evita llenar la caché con datos que rara vez se leen. Desventaja: Lecturas iniciales después de una escritura pueden ser lentas.
Integración con CDN y Edge Caching
Para un rendimiento óptimo, el caching no debe limitarse al backend. La combinación de caching de backend (con Redis/Memcached) y caching de borde (con CDN) es una estrategia poderosa. Las CDN no solo almacenan contenido estático, sino que las modernas soluciones de «Edge Computing» (ej., Cloudflare Workers, AWS Lambda@Edge) permiten ejecutar lógica de aplicación en los PoPs de la CDN, habilitando el caching de respuestas dinámicas más cerca del usuario.
Esto reduce la carga del servidor de origen en un porcentaje aún mayor (hasta un 90% para ciertos tipos de contenido), mejorando la experiencia del usuario a escala global y reduciendo los costos de transferencia de datos.
CASOS DE USO
Casos de Uso y Ejemplos del Mundo Real
El caching es una técnica versátil que se puede aplicar a una multitud de escenarios para mejorar el rendimiento y la escalabilidad de las aplicaciones. Aquí exploramos algunos de los casos de uso más comunes y efectivos en 2026.
1. Páginas de Productos en E-commerce
Caching de Datos de Producto
Descripción: Las páginas de productos son algunas de las más visitadas en sitios de e-commerce. Los datos de un producto (nombre, descripción, precio, imágenes, stock) a menudo se almacenan en una base de datos relacional y pueden requerir múltiples uniones para construirse. Servir esta información directamente desde Redis o Memcached reduce drásticamente el tiempo de carga de la página.
Implementación: Al cargar una página de producto, la aplicación primero busca los datos en la caché. Si no están presentes, los obtiene de la base de datos, los serializa (ej. a JSON) y los almacena en la caché con un TTL (ej. 30 minutos). Cuando un producto se actualiza, la entrada de la caché para ese producto específico se invalida.
2. Feeds de Redes Sociales y Contenido Personalizado
Las plataformas de redes sociales deben servir feeds personalizados a millones de usuarios en tiempo real. Construir un feed para cada usuario implica consultar múltiples fuentes de datos (publicaciones de amigos, recomendaciones, anuncios). El caching es vital aquí.
Implementación: Se puede pre-generar y almacenar el feed de cada usuario en Redis (usando listas o conjuntos ordenados) o Memcached. Cuando un usuario solicita su feed, se sirve directamente desde la caché. Cuando se publica nuevo contenido, se actualizan los feeds relevantes en la caché. Redis es particularmente útil aquí por sus estructuras de datos.
3. Gestión de Sesiones de Usuario
En aplicaciones distribuidas (especialmente microservicios), mantener el estado de la sesión de un usuario en la memoria local del servidor es problemático. Si el usuario es redirigido a otro servidor, la sesión se pierde. Almacenar sesiones en una caché distribuida resuelve esto.
Implementación: Los datos de sesión (ID de usuario, preferencias, carrito de compras) se almacenan en Redis o Memcached, con la clave siendo el ID de sesión del usuario. Esto permite que cualquier servidor de aplicación acceda a los datos de la sesión, facilitando la escalabilidad horizontal y la alta disponibilidad. Redis es preferible si se necesita persistencia o estructuras de datos más complejas para la sesión.
4. Rate Limiting (Limitación de Tasa)
Para proteger las APIs de abusos o sobrecargas, se implementa la limitación de tasa. Redis es una excelente opción para este fin debido a sus comandos atómicos y tipos de datos.
Implementación: Se pueden usar contadores de Redis para rastrear el número de solicitudes por usuario o IP dentro de un período de tiempo. Por ejemplo, un INCR para cada solicitud y un EXPIRE en la clave del contador. Esto permite una limitación de tasa precisa y distribuida.
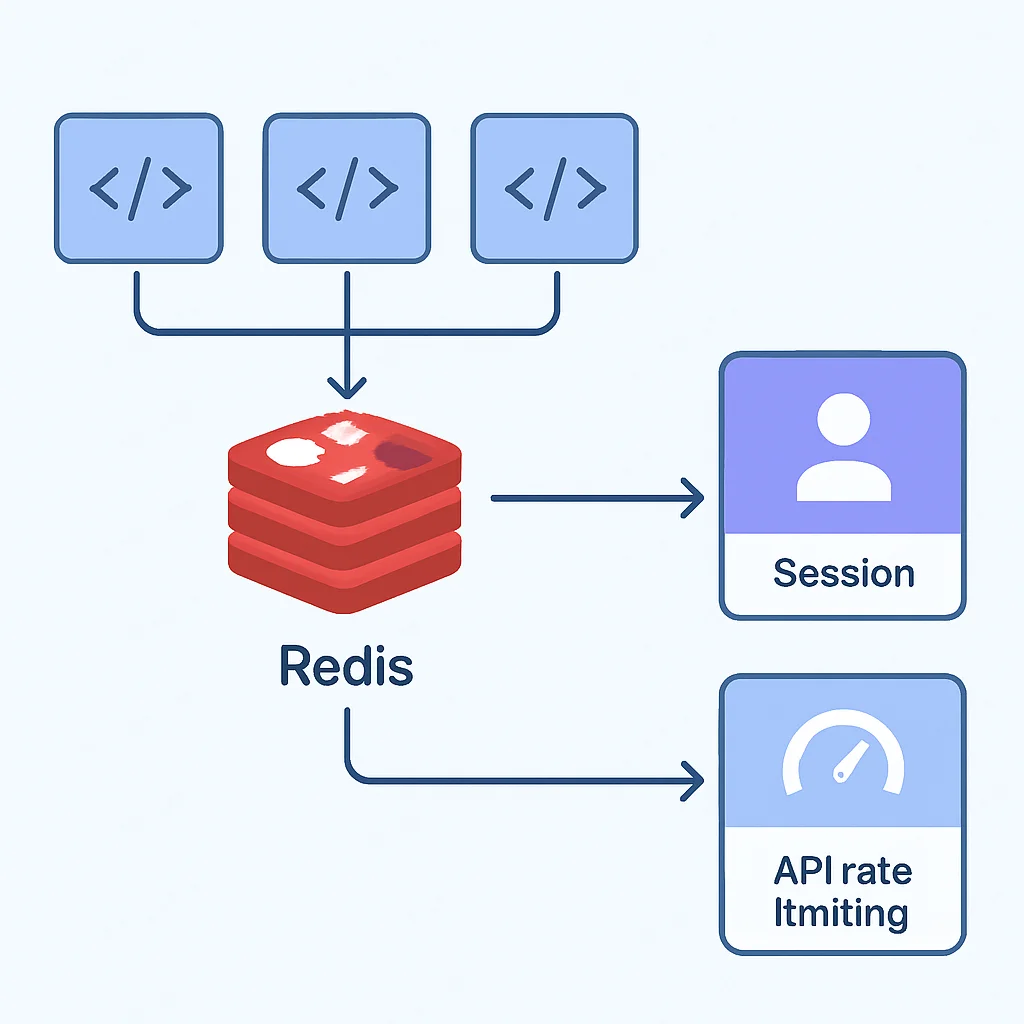
FUTURO
El Futuro del Caching: Tendencias para 2026 y Más Allá
El paisaje del caching está en constante evolución, impulsado por nuevas arquitecturas, tecnologías y demandas de rendimiento. En 2026 y más allá, podemos esperar ver varias tendencias clave que darán forma a cómo implementamos y gestionamos las cachés.
1. Caching Serverless y Edge Computing
Con el auge de las arquitecturas serverless, el caching se está moviendo cada vez más hacia el «borde» de la red. Servicios como AWS ElastiCache for Serverless, Cloudflare Workers y AWS Lambda@Edge permiten a los desarrolladores implementar lógica de caching directamente en ubicaciones geográficamente cercanas a los usuarios. Esto reduce drásticamente la latencia al evitar