

La optimización de bases de datos NoSQL es crucial para la escalabilidad y el rendimiento en el panorama tecnológico de 2026.
En este informe, analizamos las estrategias más efectivas para maximizar la eficiencia de sus sistemas NoSQL, abordando desde el particionamiento hasta la indexación avanzada y el monitoreo continuo. Descubra cómo Kwonsejo puede ayudarle a transformar su infraestructura de datos para los desafíos del futuro.
Contents
01Contexto: La Evolución de las Bases de Datos NoSQL en 2026
02Análisis Comparativo de Estrategias de Optimización
03Implementación Práctica y Casos de Uso
Contexto: La Evolución de las Bases de Datos NoSQL en 2026
En el dinámico panorama tecnológico de 2026, las bases de datos NoSQL se han consolidado como pilares fundamentales para aplicaciones modernas que demandan alta disponibilidad, escalabilidad horizontal y flexibilidad de esquemas. A medida que los volúmenes de datos continúan creciendo exponencialmente y la velocidad de acceso se vuelve más crítica, la optimización de estos sistemas es más vital que nunca. Empresas de todos los tamaños, desde startups ágiles hasta corporaciones globales, confían en soluciones NoSQL como MongoDB, Cassandra, Redis y DynamoDB para impulsar sus servicios.
La adopción masiva se debe a su capacidad para manejar datos no estructurados y semiestructurados, lo que las hace ideales para casos de uso como análisis de big data, IoT, redes sociales y microservicios. Sin embargo, esta flexibilidad viene con el desafío inherente de asegurar un rendimiento óptimo bajo cargas extremas y una gestión eficiente de los recursos.
El verdadero valor de una base de datos NoSQL se manifiesta solo cuando su arquitectura y configuración están meticulosamente optimizadas para el patrón de acceso y el volumen de datos.
Retos Actuales de Escalabilidad
A pesar de su diseño inherentemente escalable, las bases de datos NoSQL no son inmunes a los cuellos de botella. Los retos comunes incluyen la gestión ineficiente de la memoria, consultas mal optimizadas, un particionamiento de datos inadecuado y la falta de monitoreo proactivo. Según un estudio de IDC de 2025, el 45% de las empresas experimentan problemas de rendimiento críticos en sus sistemas NoSQL al alcanzar ciertos umbrales de datos o usuarios, lo que subraya la necesidad de estrategias de optimización robustas.
Un ejemplo práctico es una aplicación de comercio electrónico que experimenta latencia durante picos de ventas. Si la base de datos de productos (ej. MongoDB) no está correctamente indexada o si la colección de sesiones de usuario (ej. Redis) no se gestiona con políticas de expiración adecuadas, el sistema puede colapsar rápidamente, resultando en pérdidas económicas y daño a la reputación.
Análisis Comparativo de Estrategias de Optimización
La optimización de bases de datos NoSQL abarca diversas técnicas, cada una con sus propias ventajas y consideraciones. Es fundamental seleccionar la estrategia adecuada en función del modelo de datos, los patrones de acceso y los requisitos de consistencia y disponibilidad.
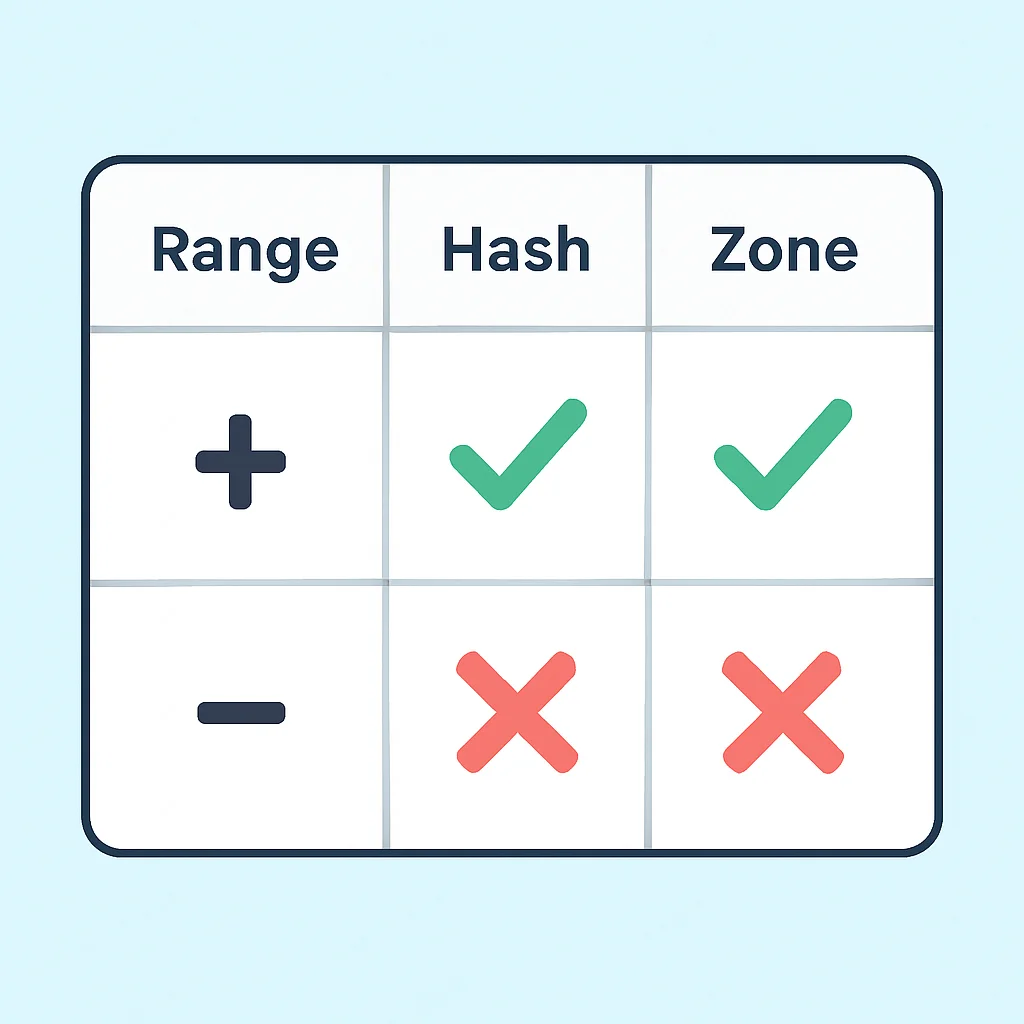
Sharding y Particionamiento
El sharding, o particionamiento horizontal, es la técnica más común para escalar bases de datos NoSQL distribuyendo los datos a través de múltiples nodos. Esto permite que las consultas se ejecuten en conjuntos de datos más pequeños y que la carga de trabajo se distribuya, mejorando significativamente el rendimiento y la capacidad.
La clave del sharding efectivo reside en la elección de una "clave de shard" adecuada. Una clave mal elegida puede conducir a "hot spots" (nodos con una carga desproporcionadamente alta) o a una distribución desigual de los datos, anulando los beneficios de la escalabilidad. Por ejemplo, en MongoDB, si se usa una clave de shard basada en un campo con pocos valores únicos o un campo que crece monótonamente, como un timestamp, puede resultar en que la mayoría de las inserciones vayan a un solo shard.
Consideremos un ejemplo de configuración de sharding en MongoDB, donde se busca distribuir documentos de usuarios basándose en un ID de usuario hashed para asegurar una distribución uniforme:
// Conectarse a la instancia de mongos
mongo --host mongos-host:27017
// Habilitar sharding en la base de datos
sh.enableSharding("miBaseDeDatos")
// Crear un índice en la clave de shard
db.usuarios.createIndex({ "usuarioId": "hashed" })
// Shardear la colección 'usuarios' usando la clave 'usuarioId' con hash
sh.shardCollection("miBaseDeDatos.usuarios", { "usuarioId": "hashed" })
Este enfoque de sharding hashed distribuye los documentos de manera más uniforme, evitando hot spots que podrían ocurrir con un sharding de rango en un campo incremental.
Indexación Avanzada
Los índices son estructuras de datos que mejoran la velocidad de las operaciones de búsqueda en una base de datos. Sin embargo, un exceso de índices o índices mal diseñados pueden ralentizar las operaciones de escritura y consumir recursos de almacenamiento valiosos. La clave es crear índices selectivos que soporten los patrones de consulta más frecuentes sin sobrecargar el sistema.
En bases de datos como Cassandra, la indexación funciona de manera diferente a las bases de datos relacionales tradicionales. Los índices secundarios en Cassandra deben usarse con precaución, ya que pueden generar escaneos de tabla completos en grandes clústeres. En su lugar, se prefieren las tablas de agregación o los índices basados en la clave de partición para optimizar las consultas.
La implementación cuidadosa de índices compuestos y parciales puede reducir drásticamente los tiempos de respuesta de las consultas complejas.
Por ejemplo, un índice compuesto en un sistema de gestión de pedidos podría incluir estadoPedido y fechaPedido, permitiendo búsquedas rápidas de "pedidos pendientes en el último mes". Un índice parcial podría aplicarse solo a documentos con un campo específico, reduciendo el tamaño del índice y mejorando el rendimiento para ciertos subconjuntos de datos.
Implementación Práctica y Casos de Uso
La teoría es solo una parte de la ecuación; la aplicación práctica de estas estrategias de optimización es donde realmente se generan resultados. A continuación, exploramos cómo estas técnicas se aplican a algunas de las bases de datos NoSQL más populares.
Optimización con MongoDB
MongoDB es una base de datos de documentos altamente flexible que se beneficia enormemente de una cuidadosa planificación de esquemas e indexación. Además del sharding, la optimización de MongoDB a menudo implica:
- Modelado de datos embebido vs. referenciado: Decidir si incrustar documentos relacionados o referenciarlos. La incrustación reduce el número de consultas pero puede aumentar el tamaño del documento; las referencias aumentan las consultas pero mantienen los documentos pequeños.
- Índices TTL (Time-To-Live): Para colecciones con datos que caducan, como sesiones de usuario o logs. Permiten a MongoDB eliminar documentos automáticamente después de un período de tiempo, liberando espacio y recursos.
- Índices parciales: Indexar solo los documentos de una colección que satisfacen una condición específica. Esto puede reducir el tamaño del índice y mejorar el rendimiento de las operaciones de escritura.
Un caso de uso común para índices TTL es la gestión de datos de telemetría o IoT, donde los datos son valiosos solo por un período limitado antes de ser archivados o descartados. Si no se gestionan, estas colecciones pueden crecer rápidamente, afectando el rendimiento general.
Ejemplo de creación de un índice TTL en MongoDB para una colección de logs:
// Crear un índice TTL en el campo 'createdAt' que expira después de 7 días (604800 segundos)
db.logs.createIndex( { "createdAt": 1 }, { expireAfterSeconds: 604800 } )
Estrategias para Cassandra
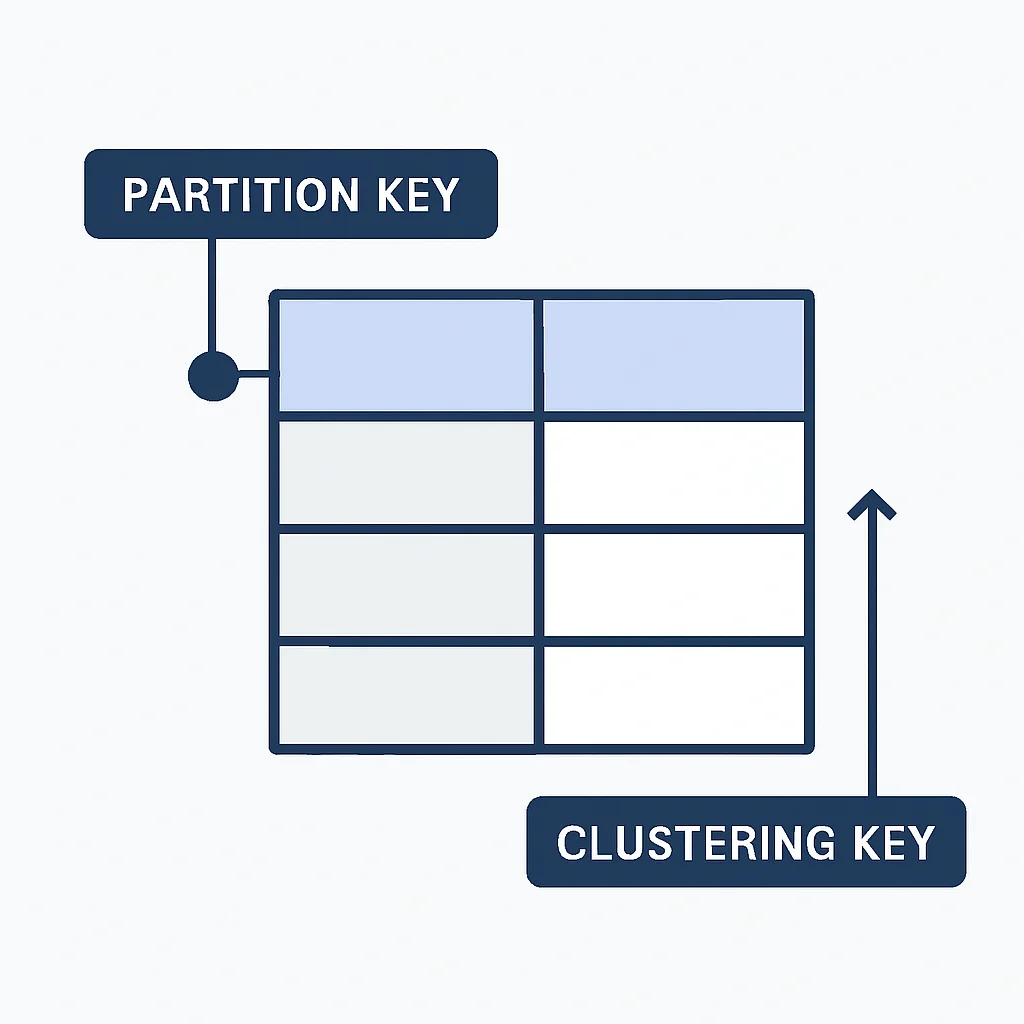
Cassandra, conocida por su alta disponibilidad y tolerancia a fallos, requiere un modelado de datos que priorice los patrones de consulta. A diferencia de MongoDB, Cassandra no tiene un concepto de "índices secundarios" en el mismo sentido, y las consultas deben diseñarse en torno a las claves de partición y agrupamiento.
- Modelado de datos centrado en la consulta: Diseñar tablas específicas para cada patrón de consulta único, incluso si esto significa duplicar datos. Esto es fundamental para evitar escaneos de tabla completos.
- Claves de partición y agrupamiento: La clave de partición distribuye los datos entre los nodos, mientras que la clave de agrupamiento ordena los datos dentro de una partición. Una buena combinación es vital para el rendimiento.
- Compresión: Utilizar algoritmos de compresión para reducir el tamaño de los datos en disco, lo que puede mejorar la E/S y el rendimiento general.
Por ejemplo, si se necesita consultar usuarios por ciudad y edad, en lugar de crear un índice secundario en cada campo, se podría crear una tabla específica donde la clave de partición sea ciudad y la clave de agrupamiento sea edad.
// Ejemplo de tabla en Cassandra optimizada para consultas por ciudad y edad
CREATE TABLE usuarios_por_ciudad_edad (
ciudad text,
edad int,
usuario_id uuid,
nombre text,
PRIMARY KEY ((ciudad), edad)
);
// Consulta eficiente:
SELECT * FROM usuarios_por_ciudad_edad WHERE ciudad = 'Madrid' AND edad > 30;
Esta aproximación garantiza que todas las consultas para una ciudad específica se realicen dentro de una única partición, minimizando la latencia de red y maximizando la eficiencia.
Monitoreo y Mantenimiento Continuo
La optimización de una base de datos NoSQL no es un evento único, sino un proceso continuo. El monitoreo proactivo y el mantenimiento regular son esenciales para identificar y resolver problemas de rendimiento antes de que afecten a los usuarios finales. Esto incluye la vigilancia de métricas clave, la auditoría de consultas y la planificación de capacidad.
Herramientas de Observabilidad
Para mantener el rendimiento óptimo, es crucial tener visibilidad sobre el estado de la base de datos. Herramientas de monitoreo como Prometheus, Grafana, Datadog o las soluciones nativas de los proveedores (ej. MongoDB Atlas Monitoring, Cassandra OpsCenter) permiten rastrear métricas como:
- Latencia de lectura/escritura: Tiempo que tardan las operaciones en completarse.
- Uso de CPU y memoria: Recursos consumidos por los nodos de la base de datos.
- Conexiones activas: Número de clientes conectados a la base de datos.
- Tamaño de la base de datos/colección: Crecimiento y distribución del almacenamiento.
- Errores y excepciones: Incidencias que pueden indicar problemas subyacentes.
Establecer alertas para umbrales críticos de estas métricas es fundamental para una respuesta rápida ante posibles degradaciones de rendimiento. Por ejemplo, una latencia de lectura que supere los 50ms de forma consistente podría indicar la necesidad de optimizar índices o añadir más shards.

Perspectivas Futuras y Conclusión
El futuro de las bases de datos NoSQL se vislumbra con una mayor integración con tecnologías de inteligencia artificial y machine learning, así como una evolución hacia arquitecturas aún más distribuidas y autónomas. La optimización continuará siendo un factor clave, pero las herramientas y metodologías se volverán más sofisticadas.
Bases de Datos Distribuidas y Edge Computing
La creciente tendencia hacia el edge computing y las arquitecturas de datos distribuidas significa que las bases de datos NoSQL se implementarán cada vez más cerca de la fuente de datos. Esto reducirá la latencia y mejorará la resiliencia. La optimización en este contexto implicará no solo la gestión de datos en el centro de datos, sino también en miles de nodos en el "borde" de la red. Soluciones como Couchbase Mobile o LiteDB están ganando tracción en este espacio.
La capacidad de sincronizar datos de manera eficiente entre el borde y la nube será un diferenciador clave, y la optimización se centrará en la consistencia eventual y la resolución de conflictos a escala masiva.
En Kwonsejo, estamos comprometidos con la innovación constante para ayudar a nuestros clientes a navegar estos desafíos y capitalizar las oportunidades emergentes.
La optimización NoSQL es su ventaja competitiva para el éxito en 2026.
En Kwonsejo, ofrecemos experiencia profunda en la arquitectura, implementación y optimización de bases de datos NoSQL. Contáctenos hoy para transformar su infraestructura de datos y asegurar que sus aplicaciones operen con la máxima eficiencia y escalabilidad. Su futuro digital comienza con una base de datos optimizada.