
RESUMEN
Construyendo Sistemas RAG con LLMs y Bases de Datos Vectoriales
Desarrolla sistemas de Generación Aumentada por Recuperación (RAG) para potenciar tus LLMs con conocimiento externo.
Keywords: LLMs, RAG, Bases de datos vectoriales
ÍNDICE
ÍNDICE
1. Introducción: La Necesidad de RAG en 2026
2. Arquitectura de un Sistema RAG: Componentes Clave
3. Desafíos y Soluciones en la Implementación de RAG
4. Guía Práctica: Construyendo un Sistema RAG con Python
5. Ventajas y Desventajas de RAG
6. Preguntas Frecuentes (FAQ)
CONTEXTO
Introducción: La Necesidad de RAG en 2026
En el dinámico panorama de la Inteligencia Artificial de 2026, los Grandes Modelos de Lenguaje (LLMs) como GPT-4, Llama 3 y Gemini han demostrado capacidades impresionantes para generar texto coherente y contextualmente relevante. Sin embargo, su conocimiento está intrínsecamente limitado a los datos con los que fueron entrenados, lo que a menudo lleva a «alucinaciones», respuestas desactualizadas o una incapacidad para acceder a información específica y propietaria. Aquí es donde los sistemas de Generación Aumentada por Recuperación (RAG) se vuelven indispensables.
Un sistema RAG permite a un LLM consultar una base de conocimiento externa y actualizada en tiempo real antes de formular una respuesta. Esto no solo mejora drásticamente la precisión y la relevancia de las salidas del modelo, sino que también reduce las alucinaciones y proporciona una fuente verificable para la información generada. Para las empresas y desarrolladores en 2026, la implementación de RAG no es solo una mejora, sino una estrategia fundamental para construir aplicaciones de IA robustas, fiables y transparentes.
Consideremos un escenario típico: una empresa necesita un chatbot de soporte al cliente que pueda responder preguntas sobre sus últimos productos y políticas internas. Entrenar un LLM desde cero con estos datos sería costoso, lento y requeriría un re-entrenamiento constante a medida que la información cambia. Con RAG, el LLM puede consultar una base de datos vectorial que contiene documentos de productos, manuales y políticas actualizadas, garantizando que sus respuestas sean siempre precisas y estén al día. Este enfoque híbrido combina la fluidez generativa de los LLMs con la precisión y la actualidad de una base de datos externa.
PUNTO CLAVE
Los sistemas RAG son esenciales en 2026 para superar las limitaciones de conocimiento de los LLMs, ofreciendo respuestas precisas, actualizadas y verificables al integrar bases de datos externas.
ANÁLISIS DETALLADO
Arquitectura de un Sistema RAG: Componentes Clave
La implementación de un sistema RAG implica la orquestación de varios componentes que trabajan en conjunto para recuperar información relevante y utilizarla en la generación de respuestas. Comprender cada parte es crucial para diseñar una arquitectura eficiente.
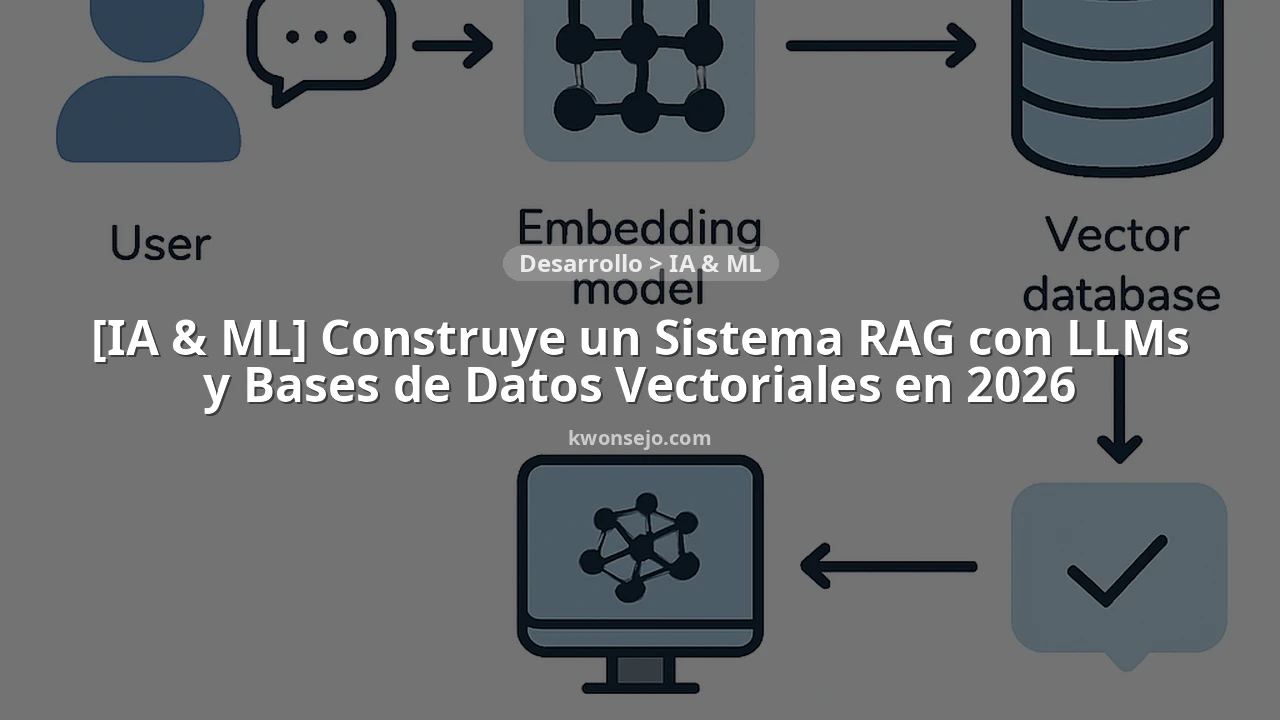
1. Base de Conocimiento Externa
Esta es la fuente de datos que el LLM consultará. Puede ser cualquier tipo de información: documentos PDF, bases de datos SQL, artículos de blog, wikis internas, grabaciones de audio transcritas, etc. La clave es que esta información esté actualizada y sea relevante para el dominio de la aplicación.
2. Modelo de Embeddings (Encoder)
Antes de que la información pueda ser buscada de manera eficiente, debe transformarse en un formato que las máquinas puedan entender y comparar semánticamente. Los modelos de embeddings convierten texto (o cualquier otro tipo de dato) en vectores numéricos de alta dimensión, donde la distancia entre vectores representa la similitud semántica. Modelos como Sentence-BERT o los embeddings de OpenAI son ejemplos populares en 2026.
3. Base de Datos Vectorial
Una vez que los documentos de la base de conocimiento se han convertido en embeddings, se almacenan en una base de datos vectorial. Estas bases de datos están optimizadas para la búsqueda de similitud vectorial (Nearest Neighbor Search o Approximate Nearest Neighbor – ANN), lo que permite encontrar rápidamente los fragmentos de texto más relevantes para una consulta dada. Ejemplos incluyen Pinecone, Weaviate, Milvus, Qdrant y ChromaDB.
Comparativa de Bases de Datos Vectoriales (2026)
Pinecone — Solución SaaS gestionada, escalable y de alto rendimiento. Ideal para producción a gran escala. Costo basado en uso.
Weaviate — Base de datos vectorial de código abierto con capacidades de búsqueda semántica y GraphQL. Despliegue auto-gestionado o en la nube.
Milvus — Base de datos vectorial de código abierto de grado empresarial, altamente escalable y robusta. Requiere gestión de infraestructura.
Qdrant — Base de datos vectorial de código abierto con capacidades de filtrado avanzado y baja latencia. Despliegue flexible.
ChromaDB — Base de datos vectorial ligera de código abierto, ideal para prototipos y aplicaciones de menor escala. Fácil de usar.
4. Módulo de Recuperación (Retriever)
Cuando un usuario realiza una consulta, esta se convierte en un embedding utilizando el mismo modelo de embeddings. El módulo de recuperación toma este vector de consulta y lo utiliza para buscar en la base de datos vectorial los fragmentos de texto más similares. El resultado son N fragmentos de texto (o «chunks») que son semánticamente relevantes para la pregunta del usuario.
5. Gran Modelo de Lenguaje (LLM – Generator)
Finalmente, la consulta original del usuario junto con los fragmentos de texto recuperados se envían al LLM. El LLM utiliza esta información como contexto adicional para generar una respuesta más precisa y fundamentada. Por ejemplo, la prompt podría estructurarse así: «Basado en la siguiente información: [fragmentos recuperados], responde a la pregunta: [pregunta del usuario]».
La sinergia entre estos componentes es lo que hace que RAG sea tan poderoso. Permite que los LLMs accedan a un universo de conocimiento que va más allá de sus datos de entrenamiento, manteniéndolos actualizados y reduciendo la probabilidad de errores o información obsoleta. La elección de cada componente (modelo de embedding, base de datos vectorial, LLM) dependerá de los requisitos específicos de rendimiento, costo y escalabilidad de tu aplicación.
PUNTO CLAVE
Un sistema RAG efectivo se basa en la interacción fluida entre una base de conocimiento, un modelo de embeddings, una base de datos vectorial, un módulo de recuperación y un LLM generador.
RESOLUCIÓN DE PROBLEMAS
Desafíos y Soluciones en la Implementación de RAG
Aunque los sistemas RAG ofrecen beneficios significativos, su implementación no está exenta de desafíos. Abordar estos problemas de manera proactiva es clave para construir un sistema robusto y eficiente.
PROBLEMA 01
Latencia y Escalabilidad del Recuperador
A medida que la base de conocimiento crece a millones o miles de millones de documentos, la búsqueda de similitud vectorial puede volverse lenta, afectando el tiempo de respuesta del sistema RAG. La latencia puede ser crítica para aplicaciones en tiempo real.
SOLUCIÓN — Optimización de la Base de Datos Vectorial y Estrategias de Indexación
Utiliza bases de datos vectoriales optimizadas para ANN (Approximate Nearest Neighbor) que ofrecen un equilibrio entre velocidad y precisión. Implementa estrategias de indexación avanzadas como HNSW (Hierarchical Navigable Small Worlds) o IVF (Inverted File Index) para acelerar las búsquedas. Considera el uso de hardware especializado (GPUs) para la generación de embeddings y la búsqueda vectorial en cargas de trabajo muy altas. Además, la fragmentación (sharding) de la base de datos vectorial puede distribuir la carga y mejorar la escalabilidad horizontal. En 2026, los proveedores de bases de datos vectoriales como Pinecone y Milvus ofrecen optimizaciones automáticas y escalabilidad elástica para manejar estos desafíos.
PROBLEMA 02
Calidad de los Embeddings y Relevancia de la Recuperación
Si los embeddings generados no capturan adecuadamente el significado semántico del texto, el módulo de recuperación puede fallar en encontrar los fragmentos más relevantes, llevando a respuestas de baja calidad o incorrectas por parte del LLM.
SOLUCIÓN — Selección de Modelos de Embeddings y Re-rankers
Elige modelos de embeddings que estén pre-entrenados en dominios similares a tus datos o que puedan ser ajustados (fine-tuned) con tus propios datos. Modelos especializados en el dominio, si están disponibles, suelen superar a los modelos genéricos. Además, implementa un módulo de re-ranking después de la recuperación inicial. Un re-ranker (a menudo un modelo más pequeño y especializado) toma los N fragmentos recuperados y los ordena según una mayor relevancia contextual para la consulta. Esto asegura que los fragmentos más útiles sean los primeros en presentarse al LLM. Técnicas como la «expansión de consulta» (query expansion) o la «reescritura de consulta» (query rewriting) también pueden mejorar la calidad de los embeddings de la consulta inicial.
PROBLEMA 03
Gestión de la Ventana de Contexto del LLM
Los LLMs tienen una longitud máxima de entrada (ventana de contexto). Si los fragmentos recuperados son demasiado largos o numerosos, excederán esta ventana, lo que obligará a truncar la información o a generar errores, degradando la calidad de la respuesta.
SOLUCIÓN — Estrategias de Chunking y Resumen
Optimiza la estrategia de «chunking» (fragmentación) de tus documentos. Los chunks deben ser lo suficientemente pequeños para caber en la ventana de contexto, pero lo suficientemente grandes para contener información significativa. Experimenta con diferentes tamaños y solapamientos de chunks. También puedes considerar técnicas de resumen: si un chunk es muy largo, puedes usar un LLM más pequeño para resumirlo antes de pasarlo al LLM principal. Otra opción es la «recuperación jerárquica», donde primero se recuperan chunks de alto nivel (ej. títulos de secciones) y luego se profundiza en chunks más detallados si es necesario. En 2026, los LLMs de nueva generación ofrecen ventanas de contexto mucho más grandes (hasta 1 millón de tokens en algunos casos), lo que alivia este problema, pero una buena gestión sigue siendo crucial.
PUNTO CLAVE
La implementación exitosa de RAG requiere la optimización de la búsqueda vectorial, la selección cuidadosa de modelos de embeddings, el uso de re-rankers y una gestión inteligente de la ventana de contexto del LLM.
APLICACIÓN PRÁCTICA
Guía Práctica: Construyendo un Sistema RAG con Python
Vamos a construir un sistema RAG simplificado usando Python, el framework LangChain para la orquestación y ChromaDB como base de datos vectorial. Este ejemplo te dará una base sólida para entender el flujo completo.
Paso 1: Preparación de Datos y Generación de Embeddings
Primero, necesitamos cargar nuestros documentos y dividirlos en chunks. Luego, generaremos embeddings para cada chunk.
EXPLICACIÓN DEL CÓDIGO
Este código carga un documento de texto simple, lo divide en fragmentos de 1000 caracteres con un solapamiento de 200, y luego inicializa un modelo de embeddings de OpenAI. Asegúrate de tener tu clave de API de OpenAI configurada como variable de entorno.
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
import os
# 1. Cargar el documento
# Simulamos un documento de ejemplo. En un caso real, esto sería un archivo.
document_content = """
El sistema solar es un sistema planetario que orbita alrededor de una única estrella, el Sol.
Está compuesto por ocho planetas principales: Mercurio, Venus, Tierra, Marte, Júpiter, Saturno, Urano y Neptuno.
Además de los planetas, el sistema solar incluye planetas enanos como Plutón, asteroides, cometas y una gran cantidad de satélites naturales.
La Tierra es el tercer planeta desde el Sol y el único conocido por albergar vida. Su atmósfera rica en oxígeno y su abundante agua líquida son cruciales.
Marte, conocido como el planeta rojo, ha sido objeto de intensa exploración debido a la posibilidad de vida pasada o presente.
Júpiter es el planeta más grande del sistema solar, una gigante gaseoso con una gran mancha roja, una tormenta persistente.
Saturno es famoso por sus impresionantes anillos, compuestos principalmente por partículas de hielo.
Urano y Neptuno son gigantes de hielo, los más alejados del Sol.
La formación del sistema solar se estima en unos 4.600 millones de años a partir del colapso gravitacional de una pequeña parte de una nube molecular gigante.
"""
# Guardar contenido en un archivo temporal para TextLoader
with open("solar_system.txt", "w", encoding="utf-8") as f:
f.write(document_content)
loader = TextLoader("solar_system.txt", encoding="utf-8")
documents = loader.load()
# 2. Dividir el documento en chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = text_splitter.split_documents(documents)
print(f"Número de chunks generados: {len(chunks)}")
# print(f"Primer chunk: {chunks[0].page_content[:150]}...")
# 3. Inicializar el modelo de embeddings
# Asegúrate de tener OPENAI_API_KEY configurada en tus variables de entorno
# os.environ["OPENAI_API_KEY"] = "TU_CLAVE_AQUI" # ¡No hagas esto en producción!
embeddings_model = OpenAIEmbeddings()
print("Modelo de embeddings inicializado correctamente.")
Paso 2: Almacenamiento en Base de Datos Vectorial (ChromaDB)
Ahora, tomaremos nuestros chunks y sus embeddings y los almacenaremos en ChromaDB, una base de datos vectorial ligera y fácil de usar.
EXPLICACIÓN DEL CÓDIGO
Este fragmento de código crea una instancia de ChromaDB a partir de los chunks y el modelo de embeddings definidos anteriormente. La base de datos vectorial se persistirá localmente en un directorio llamado ./chroma_db.
from langchain_community.vectorstores import Chroma
# 4. Almacenar chunks y embeddings en ChromaDB
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embeddings_model,
persist_directory="./chroma_db" # Guarda la base de datos localmente
)
# Persistir la base de datos (opcional, si se quiere cargar más tarde)
vectorstore.persist()
print("Base de datos vectorial ChromaDB creada y persistida.")
# Limpiar el archivo temporal
os.remove("solar_system.txt")
Paso 3: Implementación del Flujo de Recuperación y Generación (RAG)
Finalmente, construiremos la cadena RAG que tomará una consulta, recuperará información relevante de ChromaDB y la pasará a un LLM para generar una respuesta.
EXPLICACIÓN DEL CÓDIGO
Este código carga la base de datos vectorial persistida, configura un recuperador y luego crea una cadena RAG utilizando un LLM de OpenAI. Puedes hacer preguntas y el sistema usará el contexto recuperado para responder. Observa cómo la función invoke() de la cadena RAG orquesta todo el proceso.
from langchain_openai import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain_core.prompts import PromptTemplate
# Cargar la base de datos vectorial existente
vectorstore_loaded = Chroma(
persist_directory="./chroma_db",
embedding_function=embeddings_model # Es importante usar la misma función de embedding
)
# 5. Configurar el recuperador
retriever = vectorstore_loaded.as_retriever(search_kwargs={"k": 2}) # Recuperar los 2 chunks más relevantes
# 6. Inicializar el LLM
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0) # Puedes usar "gpt-4" para mejores resultados
# 7. Crear el Prompt Template para el LLM
# Este prompt guía al LLM sobre cómo usar la información recuperada
prompt_template = """
Usa la siguiente información de contexto para responder a la pregunta del usuario.
Si no puedes encontrar la respuesta en el contexto proporcionado, di que no tienes suficiente información.
Mantén la respuesta concisa y al punto.
Contexto:
{context}
Pregunta: {question}
Respuesta:
"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
# 8. Crear la cadena RAG
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # 'stuff' junta todos los documentos en un solo prompt
retriever=retriever,
return_source_documents=True, # Para ver qué documentos se usaron
chain_type_kwargs={"prompt": PROMPT}
)
# Hacer una consulta
query = "¿Cuáles son los planetas principales del sistema solar?"
result = qa_chain.invoke({"query": query})
print(f"\nPregunta: {query}")
print(f"Respuesta: {result['result']}")
print("\nDocumentos fuente utilizados:")
for doc in result["source_documents"]:
print(f"- {doc.page_content[:100]}...")
print("\n--- Otra consulta ---")
query_2 = "¿Qué características hacen a la Tierra única?"
result_2 = qa_chain.invoke({"query": query_2})
print(f"\nPregunta: {query_2}")
print(f"Respuesta: {result_2['result']}")
print("\nDocumentos fuente utilizados:")
for doc in result_2["source_documents"]:
print(f"- {doc.page_content[:100]}...")
print("\n--- Consulta sin información en la base de datos ---")
query_3 = "¿Quién ganó el mundial de fútbol en 2018?"
result_3 = qa_chain.invoke({"query": query_3})
print(f"\nPregunta: {query_3}")
print(f"Respuesta: {result_3['result']}")
print("\nDocumentos fuente utilizados:")
for doc in result_3["source_documents"]:
print(f"- {doc.page_content[:100]}...")
PUNTO CLAVE
LangChain simplifica la construcción de sistemas RAG al proporcionar abstracciones para la carga de documentos, fragmentación, embeddings, bases de datos vectoriales y la orquestación del LLM, permitiendo un desarrollo ágil y modular.
CASOS DE USO
Aplicaciones Prácticas de RAG en 2026
Los sistemas RAG están transformando cómo interactuamos con la información y la IA en diversas industrias. Aquí hay algunos casos de uso destacados en 2026:

Chatbots de Soporte al Cliente Inteligentes
Permiten que los chatbots respondan preguntas complejas de los clientes utilizando manuales de productos, FAQs y bases de conocimiento internas actualizadas, mejorando la satisfacción del cliente y reduciendo la carga de trabajo del personal.
Asistentes de Investigación y Desarrollo
Ayudan a científicos e ingenieros a navegar por grandes volúmenes de literatura científica, patentes y documentos técnicos, resumiendo hallazgos relevantes y sugiriendo nuevas direcciones de investigación.
Sistemas de Gestión del Conocimiento Empresarial
Empoderan a los empleados con acceso instantáneo a políticas internas, procedimientos, historiales de proyectos y documentos corporativos, mejorando la productividad y la toma de decisiones.
Herramientas Legales y Financieras
Permiten a los profesionales legales y financieros analizar contratos, regulaciones, informes de mercado y datos financieros con mayor eficiencia, identificando riesgos y oportunidades.
Plataformas Educativas Personalizadas
Ofrecen a los estudiantes respuestas detalladas y contextualizadas a sus preguntas basadas en libros de texto, artículos académicos y materiales de curso específicos, adaptándose a su ritmo de aprendizaje.
ANÁLISIS DE IMPACTO
Ventajas y Desventajas de RAG
Como cualquier tecnología, RAG tiene sus fortalezas y debilidades que deben considerarse antes de su implementación.

Ventajas
✓ Mayor precisión y relevancia: Accede a información externa y actualizada, reduciendo alucinaciones y proporcionando respuestas más fidedignas.
✓ Transparencia y verificabilidad: Puede citar las fuentes de información utilizadas, permitiendo a los usuarios verificar las respuestas.
✓ Menos necesidad de re-entrenamiento: El conocimiento se actualiza en la base de datos vectorial, no en el LLM, ahorrando costos y tiempo de computación.
✓ Adaptabilidad a dominios específicos: Fácilmente adaptable a nuevos dominios de conocimiento sin modificar la arquitectura del LLM subyacente.
✓ Manejo de información propietaria: Permite a las empresas utilizar sus datos internos de forma segura y controlada con LLMs públicos o de código abierto.
Desventajas
✗ Mayor complejidad de la arquitectura: Implica gestionar múltiples componentes (embeddings, BD vectorial, retriever, LLM).
✗ Dependencia de la calidad de los datos: Si la base de conocimiento es pobre o los chunks no son relevantes, el rendimiento del RAG se degrada.
✗ Latencia adicional: La fase de recuperación añade tiempo de procesamiento antes de la generación del LLM.
✗ Costos operativos: El mantenimiento de la base de datos vectorial y los costos de inferencia de embeddings pueden ser significativos a escala.
✗ Gestión de la ventana de contexto: Todavía es un desafío asegurar que toda la información recuperada quepa en la ventana de contexto del LLM.
Preguntas Frecuentes (FAQ) sobre Sistemas RAG
Q. ¿Qué significa RAG y por qué es importante para los LLMs en 2026?
RAG significa Generación Aumentada por Recuperación. Es crucial en 2026 porque permite a los LLMs acceder y utilizar información externa y actualizada en tiempo real, superando las limitaciones de su conocimiento pre-entrenado y reduciendo las «alucinaciones».
Q. ¿Qué es una base de datos vectorial y cuál es su rol en RAG?
Una base de datos vectorial es un tipo de base de datos optimizada para almacenar y buscar vectores numéricos de alta dimensión, conocidos como embeddings. En RAG, su rol es almacenar los embeddings de los documentos de la base de conocimiento, permitiendo una búsqueda rápida y eficiente de contenido semánticamente similar a la consulta del usuario.
Q. ¿Cómo se comparan RAG y el fine-tuning de LLMs?
RAG y el fine-tuning son técnicas complementarias. El fine-tuning adapta el comportamiento o estilo del LLM a un dominio específico, mientras que RAG le proporciona al LLM acceso a nueva información factual. RAG es generalmente más rápido y económico para actualizar el conocimiento, mientras que el fine-tuning es mejor para ajustar el tono, formato o capacidades específicas del modelo.
Q. ¿Qué herramientas de Python son útiles para construir un sistema RAG?
Para construir un sistema RAG en Python, herramientas como LangChain (para orquestación), LlamaIndex (para indexación y recuperación), OpenAI o Sentence-Transformers (para embeddings), y bases de datos vectoriales como ChromaDB, Pinecone o Weaviate son muy populares y eficientes en 2026.
Q. ¿Cuáles son los principales desafíos al implementar RAG?
Los principales desafíos incluyen la latencia y escalabilidad de la búsqueda vectorial en grandes volúmenes de datos, asegurar la alta calidad de los embeddings para una recuperación relevante, y gestionar eficientemente la ventana de contexto del LLM para evitar el truncamiento de información crucial.
CIERRE
Conclusión y Perspectivas Futuras
La Generación Aumentada por Recuperación (RAG) se ha establecido firmemente como una técnica fundamental para desbloquear el verdadero potencial de los Grandes Modelos de Lenguaje en 2026. Al proporcionar a los LLMs la capacidad de acceder a una base de conocimiento externa y actualizada, RAG resuelve desafíos críticos como la desactualización del conocimiento, las alucinaciones y la falta de transparencia, abriendo un abanico de posibilidades para aplicaciones de IA más inteligentes y confiables.
La construcción de un sistema RAG, aunque implica la orquestación de varios componentes (modelos de embeddings, bases de datos vectoriales, recuperadores y LLMs), se ha vuelto cada vez más accesible gracias a frameworks como LangChain y a la madurez de las bases de datos vectoriales. Las empresas y desarrolladores que adopten RAG estarán en una posición ventajosa para crear soluciones de IA que no solo sean innovadoras, sino también precisas, verificables y capaces de adaptarse rápidamente a nuevos datos y contextos.
Mirando hacia el futuro, esperamos ver aún más avances en la eficiencia de los recuperadores, la sofisticación de los modelos de re-ranking y la integración sin fisuras de RAG en plataformas de desarrollo de IA. La promesa de LLMs que no solo generan, sino que también razonan y fundamentan sus respuestas en hechos verificables, está más cerca que nunca, y RAG es la clave para hacerla realidad.
¡Gracias por leer!
Esperamos que esta guía te haya proporcionado una comprensión clara y práctica sobre cómo construir y optimizar sistemas RAG en 2026.
¿Preguntas o comentarios? ¡Déjalos abajo! Tu feedback nos ayuda a mejorar y seguir compartiendo conocimiento en Kwonsejo.