

RESUMEN
Fine-tuning de LLMs con Hugging Face y LoRA en 2026
Guía completa para personalizar y optimizar Modelos de Lenguaje Grandes (LLMs) de manera eficiente en el entorno de desarrollo actual.
Keywords: LLMs, Hugging Face, LoRA
ÍNDICE
1. Introducción al Fine-tuning de LLMs y su Relevancia en 2026
2. Fundamentos del Fine-tuning: Enfoque Tradicional vs. PEFT
3. Hugging Face: El Ecosistema Estándar para el Desarrollo de LLMs
4. LoRA: Optimizando el Fine-tuning con Adaptadores de Bajo Rango
5. Guía Práctica: Fine-tuning de LLMs con Hugging Face y LoRA en 2026
6. Casos de Uso Avanzados y Consideraciones Éticas
7. Desafíos Comunes y Estrategias de Solución
8. Evaluación del Rendimiento Post-Fine-tuning
9. Conclusión y el Futuro del Fine-tuning de LLMs
1. Introducción al Fine-tuning de LLMs y su Relevancia en 2026
En el dinámico panorama de la Inteligencia Artificial de 2026, los Modelos de Lenguaje Grandes (LLMs) se han consolidado como una tecnología transformadora. Desde la generación de contenido hasta la asistencia en programación, su versatilidad es innegable. Sin embargo, para que estos modelos pre-entrenados con miles de millones de parámetros realmente destaquen en tareas específicas, es crucial someterlos a un proceso conocido como fine-tuning o ajuste fino. Este proceso adapta un modelo generalista a un dominio o conjunto de datos particular, desbloqueando un nivel de rendimiento y precisión que no sería posible de otra manera.
El fine-tuning tradicional, que implica reentrenar todas las capas del modelo, a menudo requiere recursos computacionales masivos y grandes volúmenes de datos etiquetados, lo que lo hace inaccesible para muchas organizaciones y desarrolladores individuales. Aquí es donde técnicas innovadoras como LoRA (Low-Rank Adaptation of Large Language Models) se vuelven indispensables. LoRA permite ajustar estos gigantescos modelos de manera eficiente, reduciendo drásticamente los requisitos de memoria y computación, y acelerando el proceso de entrenamiento.
Este artículo, desarrollado por Kwonsejo, explorará en profundidad cómo Hugging Face, la plataforma líder en herramientas de PNL, se integra con LoRA para ofrecer una solución potente y accesible para el fine-tuning de LLMs en 2026. Analizaremos los fundamentos, la implementación práctica con ejemplos de código y las consideraciones clave para aprovechar al máximo esta combinación en tus proyectos de IA.
PUNTO CLAVE
El fine-tuning es esencial para adaptar LLMs a tareas específicas, y en 2026, LoRA se ha establecido como una técnica crítica para lograr esta adaptación de manera eficiente, superando las limitaciones de recursos del fine-tuning tradicional.
2. Fundamentos del Fine-tuning: Enfoque Tradicional vs. PEFT
Para comprender la relevancia de LoRA, es fundamental entender los dos enfoques principales de fine-tuning de LLMs: el tradicional y las técnicas de Adaptación Eficiente de Parámetros (PEFT, por sus siglas en inglés).
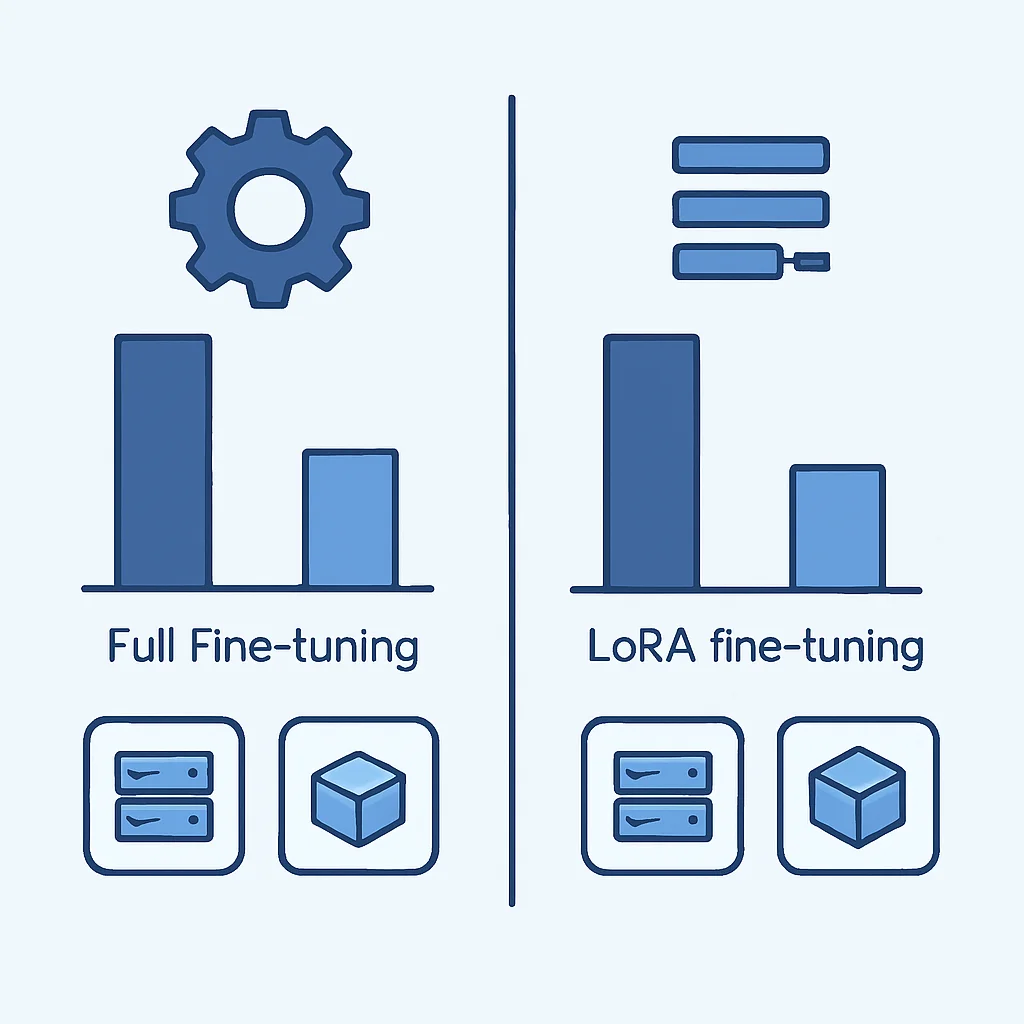
Fine-tuning Tradicional (Full Fine-tuning)
El fine-tuning tradicional implica la actualización de todos los parámetros del modelo pre-entrenado utilizando un nuevo conjunto de datos. Este método es el más directo y a menudo produce los mejores resultados en términos de rendimiento del modelo. Sin embargo, sus desventajas son significativas:
- Alto coste computacional: Reentrenar modelos con miles de millones de parámetros requiere GPUs de alta gama y mucho tiempo.
- Grandes requisitos de almacenamiento: Cada modelo ajustado resulta en una copia completa del modelo original, lo que consume una cantidad considerable de espacio.
- Riesgo de sobreajuste: Con conjuntos de datos pequeños, reentrenar todos los parámetros puede llevar al modelo a memorizar los datos de entrenamiento, perdiendo su capacidad de generalización.
- Dificultad de despliegue: Mantener múltiples versiones de modelos gigantescos para diferentes tareas complica el despliegue y la gestión.
Técnicas de Adaptación Eficiente de Parámetros (PEFT)
Las técnicas PEFT surgieron para mitigar las limitaciones del fine-tuning tradicional. En lugar de actualizar todos los parámetros del modelo, PEFT se enfoca en entrenar solo un pequeño subconjunto de parámetros adicionales o adaptar los existentes, manteniendo la mayor parte del modelo pre-entrenado congelado. Esto reduce drásticamente los recursos necesarios y el tamaño del modelo resultante.
Beneficios Clave de PEFT
Eficiencia Computacional — Reduce significativamente el uso de GPU y el tiempo de entrenamiento.
Ahorro de Almacenamiento — Los adaptadores son mucho más pequeños que el modelo base, facilitando el almacenamiento de múltiples adaptaciones.
Menor Riesgo de Sobreajuste — Al entrenar menos parámetros, se reduce la probabilidad de sobreajuste en conjuntos de datos pequeños.
Flexibilidad — Permite la creación rápida de múltiples adaptaciones para diversas tareas sin modificar el modelo base.
A continuación, se presenta una tabla comparativa que resume las diferencias fundamentales entre el fine-tuning tradicional y LoRA, una de las técnicas PEFT más destacadas en 2026:
| Característica | Fine-tuning Tradicional | LoRA (PEFT) |
|---|---|---|
| Parámetros entrenados | Todos los parámetros del modelo (miles de millones) | Una pequeña fracción de parámetros adicionales (millones o menos) |
| Coste computacional | Muy alto (requiere GPUs de alta gama) | Bajo (puede ejecutarse en GPUs de consumo) |
| Almacenamiento del modelo | Copia completa del modelo base (decenas o cientos de GB) | Solo los adaptadores (pocos MB) |
| Riesgo de sobreajuste | Alto, especialmente con pocos datos | Bajo |
| Rendimiento | Excelente, si se tienen recursos y datos suficientes | Comparables al fine-tuning completo en muchas tareas |
| Facilidad de despliegue | Complejo con múltiples modelos | Sencillo al intercambiar adaptadores |
3. Hugging Face: El Ecosistema Estándar para el Desarrollo de LLMs
Hugging Face se ha consolidado como el epicentro para el desarrollo y despliegue de modelos de lenguaje, ofreciendo un ecosistema integral que incluye librerías de código abierto, conjuntos de datos y un hub de modelos pre-entrenados. En 2026, su relevancia es mayor que nunca, sirviendo como la infraestructura base para la mayoría de los proyectos de IA relacionados con el lenguaje.
Componentes Clave del Ecosistema Hugging Face
- Transformers Library: La joya de la corona, proporciona miles de modelos pre-entrenados para PNL, visión por computadora y audio, junto con herramientas para cargarlos, entrenarlos y utilizarlos. Es compatible con PyTorch, TensorFlow y JAX.
- Datasets Library: Una librería eficiente para cargar y procesar conjuntos de datos a gran escala, optimizada para tareas de aprendizaje automático. Incluye funciones para tokenización, mapeo y filtrado.
- Accelerate Library: Simplifica el entrenamiento distribuido y el uso de diferentes configuraciones de hardware (varias GPUs, TPU) con un mínimo cambio de código.
- PEFT Library: Una librería dedicada a la implementación de técnicas de adaptación eficiente de parámetros, incluyendo LoRA, Prefix Tuning, P-tuning y más.
- Hugging Face Hub: Un repositorio centralizado donde los usuarios pueden compartir y descubrir modelos, conjuntos de datos y demos. Actúa como un GitHub para la IA.
La facilidad de uso y la vasta comunidad de Hugging Face lo convierten en la elección preferida para trabajar con LLMs. Su abstracción de la complejidad del entrenamiento y la compatibilidad con diversas arquitecturas de modelos permiten a los desarrolladores centrarse en la experimentación y la aplicación.
PUNTO CLAVE
Hugging Face es el estándar de la industria en 2026 para la gestión y el fine-tuning de LLMs, gracias a sus librerías Transformers, Datasets, Accelerate y PEFT, y su Hub de modelos.
EXPLICACIÓN DEL CÓDIGO
Este fragmento de código demuestra cómo cargar un modelo pre-entrenado y su tokenizador asociado desde el Hugging Face Hub, un paso fundamental para cualquier tarea de fine-tuning. Utilizamos un modelo genérico de ejemplo para ilustrar el proceso.
from transformers import AutoModelForCausalLM, AutoTokenizer
# Definir el nombre del modelo a cargar desde Hugging Face Hub
# En 2026, modelos como Llama-3, Falcon-7B o Mistral-7B son comunes
model_name = "mistralai/Mistral-7B-Instruct-v0.2"
print(f"Cargando el tokenizador para {model_name}...")
tokenizer = AutoTokenizer.from_pretrained(model_name)
print(f"Cargando el modelo pre-entrenado {model_name}...")
# Cargar el modelo en precisión mixta (bfloat16) para ahorrar memoria
# Esto es una práctica común en 2026 para modelos grandes
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto", # Utiliza automáticamente bfloat16 si está disponible
device_map="auto" # Distribuye el modelo en las GPUs disponibles
)
print("Modelo y tokenizador cargados exitosamente.")
print(f"Número total de parámetros del modelo: {model.num_parameters() / 1e9:.2f} mil millones")
# Ejemplo de uso básico
prompt = "Escribe una breve historia sobre un robot que descubre la amistad."
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=100, num_return_sequences=1)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("\nRespuesta del modelo sin fine-tuning:")
print(response)
4. LoRA: Optimizando el Fine-tuning con Adaptadores de Bajo Rango
LoRA (Low-Rank Adaptation of Large Language Models) es una técnica PEFT que ha revolucionado el fine-tuning de LLMs al ofrecer una solución altamente eficiente. Introducida en 2021 y ampliamente adoptada en 2026, LoRA se basa en la idea de que los cambios necesarios para adaptar un modelo pre-entrenado a una nueva tarea tienen una estructura de bajo rango.
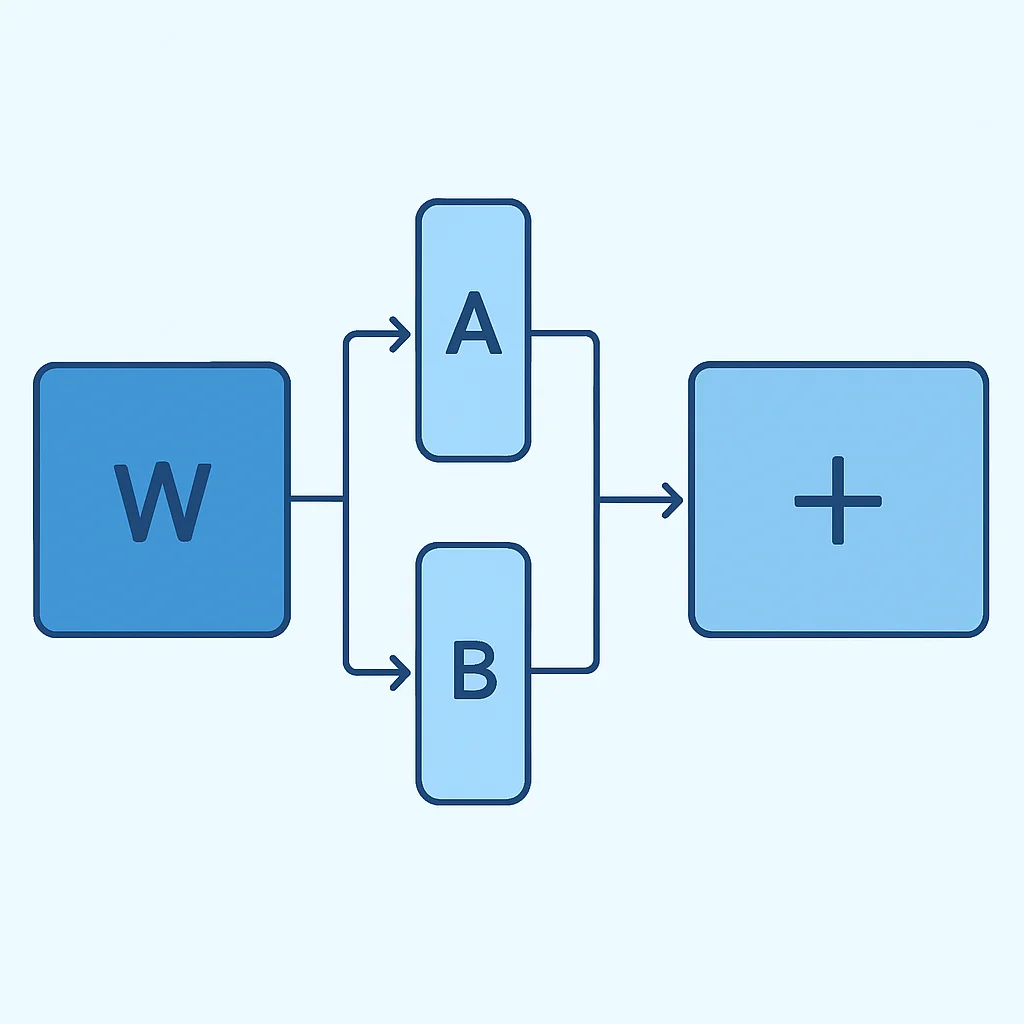
¿Cómo funciona LoRA?
En lugar de ajustar directamente las matrices de pesos originales del modelo (W), LoRA introduce pares de matrices de bajo rango (A y B) en paralelo a las matrices originales. Durante el fine-tuning, las matrices originales se congelan, y solo se entrenan las matrices A y B. El producto de estas matrices (BA) representa la actualización de bajo rango que se suma a la matriz original (W + BA). La clave aquí es que el rango de estas matrices (r) es mucho menor que las dimensiones de la matriz original, lo que reduce drásticamente el número de parámetros entrenables.
Ventajas de LoRA en 2026
- Reducción de parámetros entrenables: LoRA puede reducir los parámetros entrenables en un factor de 10,000 o más en comparación con el fine-tuning completo. Para un modelo de 7B, esto podría significar entrenar solo unos pocos millones de parámetros en lugar de 7 mil millones.
- Menor uso de memoria: Al congelar el modelo base y solo entrenar los adaptadores, se reduce significativamente el consumo de memoria de GPU, permitiendo el fine-tuning de LLMs muy grandes en hardware más modesto.
- Mayor velocidad de entrenamiento: Menos parámetros a actualizar se traduce en un fine-tuning mucho más rápido.
- Portabilidad y flexibilidad: Los adaptadores LoRA son pequeños (a menudo solo unos pocos MB), lo que facilita su almacenamiento, intercambio y aplicación a diferentes modelos base. Esto permite tener múltiples adaptaciones para un mismo modelo base sin duplicar el modelo completo.
- Rendimiento comparable: Sorprendentemente, LoRA a menudo logra un rendimiento comparable al fine-tuning completo en una amplia gama de tareas.
PUNTO CLAVE
LoRA permite que un modelo base de 7 mil millones de parámetros se ajuste finamente entrenando solo unos pocos millones de parámetros adicionales, reduciendo los requisitos de GPU en un 70-80% y los tiempos de entrenamiento en un 50-70% en comparación con el fine-tuning tradicional.
PROBLEMA 01
Altos Requisitos de Memoria y Computación para LLMs
Los LLMs modernos, como Llama-3 70B, pueden requerir cientos de GB de VRAM para el fine-tuning completo, lo que los hace inaccesibles sin clústeres de GPUs muy costosos.
SOLUCIÓN
LoRA reduce los parámetros entrenables a una fracción minúscula, permitiendo el fine-tuning de modelos de 7B-13B en una sola GPU de consumo (ej. RTX 3090/4090 con 24GB VRAM) e incluso modelos de 70B con múltiples GPUs de gama media. Esto democratiza el acceso al fine-tuning avanzado.
5. Guía Práctica: Fine-tuning de LLMs con Hugging Face y LoRA en 2026
A continuación, se presenta una guía paso a paso para realizar fine-tuning de un LLM utilizando la librería PEFT de Hugging Face y la técnica LoRA. Asumiremos que ya tienes un entorno Python configurado con PyTorch y las librerías de Hugging Face instaladas (transformers, datasets, accelerate, peft).
Paso 1
Preparación del Entorno y Carga del Modelo
Carga el modelo base y su tokenizador. Es crucial cargar el modelo en 4-bit (utilizando bitsandbytes) para reducir el consumo de VRAM, una práctica estándar en 2026 para el fine-tuning de LLMs grandes.
EXPLICACIÓN DEL CÓDIGO
Este bloque de código instala las librerías necesarias, carga un modelo LLM en cuantificación de 4 bits (load_in_4bit=True) para optimizar el uso de memoria, y configura los parámetros de LoRA. La LoraConfig define cómo y dónde se aplicarán los adaptadores de bajo rango.
# Instalación de librerías (si no están ya instaladas)
# !pip install -q -U bitsandbytes transformers peft accelerate datasets trl
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
from datasets import load_dataset
# 1. Cargar el modelo base y tokenizador
model_name = "mistralai/Mistral-7B-Instruct-v0.2" # O tu LLM preferido en 2026
# Configuración de cuantificación de 4 bits
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4", # Tipo de cuantificación
bnb_4bit_compute_dtype=torch.bfloat16 # Tipo de datos para cómputo
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token # Ajuste común para modelos causales
tokenizer.padding_side = "right" # Importante para evitar problemas de atención
# 2. Preparar el modelo para entrenamiento k-bit (4-bit)
model = prepare_model_for_kbit_training(model)
# 3. Configurar LoRA
lora_config = LoraConfig(
r=16, # Rango de las matrices LoRA (un valor común es 8, 16, 32 o 64)
lora_alpha=32, # Factor de escala para los pesos de LoRA
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"], # Módulos a los que aplicar LoRA
lora_dropout=0.05, # Dropout para las capas LoRA
bias="none", # No ajustar el sesgo
task_type="CAUSAL_LM" # Tipo de tarea para modelos de lenguaje causal
)
# 4. Obtener el modelo PEFT (LoRA)
model = get_peft_model(model, lora_config)
print(model.print_trainable_parameters())
# Ejemplo de salida: trainable params: 41,943,040 || all params: 7,241,728,000 || trainable%: 0.579169
Paso 2
Preparación del Conjunto de Datos
Carga y preprocesa tu conjunto de datos. Para el fine-tuning de LLMs, es común formatear los datos como conversaciones o instrucciones, siguiendo el formato que el modelo base espera. Utilizaremos un dataset de ejemplo del Hugging Face Hub.
EXPLICACIÓN DEL CÓDIGO
Aquí cargamos un conjunto de datos de instrucciones y lo formateamos adecuadamente para el fine-tuning. La función tokenize_function convierte el texto en tokens y añade etiquetas de atención, asegurando que el modelo aprenda correctamente de los ejemplos.
# Cargar un conjunto de datos de ejemplo (por ejemplo, Alpaca de Hugging Face)
dataset = load_dataset("tatsu-lab/alpaca", split="train")
# Función para formatear las instrucciones en un formato adecuado
def format_instruction(sample):
if sample["input"]:
return f"### Instrucción:\n{sample['instruction']}\n### Entrada:\n{sample['input']}\n### Respuesta:\n{sample['output']}"
return f"### Instrucción:\n{sample['instruction']}\n### Respuesta:\n{sample['output']}"
# Tokenizar el conjunto de datos
def tokenize_function(samples):
# Aplicar el formateo y luego tokenizar
formatted_texts = [format_instruction(s) for s in samples]
return tokenizer(
formatted_texts,
truncation=True,
max_length=512, # Longitud máxima de secuencia
padding="max_length"
)
tokenized_dataset = dataset.map(
tokenize_function,
batched=True,
remove_columns=["instruction", "input", "output", "text"] # Eliminar columnas originales
)
# Dividir el dataset para entrenamiento y validación
# Usamos un pequeño subconjunto para el ejemplo
tokenized_dataset = tokenized_dataset.train_test_split(test_size=0.01)
train_dataset = tokenized_dataset["train"]
eval_dataset = tokenized_dataset["test"]
print(f"Número de ejemplos de entrenamiento: {len(train_dataset)}")
print(f"Número de ejemplos de validación: {len(eval_dataset)}")
Paso 3
Configuración y Ejecución del Entrenamiento
Utiliza la clase TrainingArguments de Hugging Face para definir los hiperparámetros de entrenamiento y la clase Trainer para iniciar el proceso de fine-tuning.
EXPLICACIÓN DEL CÓDIGO
Este fragmento configura los argumentos del entrenamiento, incluyendo el número de épocas, el tamaño del lote, la tasa de aprendizaje y la estrategia de evaluación. Luego, inicializa el Trainer con el modelo LoRA, el tokenizador y los datasets, y finalmente ejecuta el fine-tuning. El uso de DataCollatorForLanguageModeling es crucial para preparar los datos para el entrenamiento de LLMs.
from transformers import TrainingArguments, Trainer, DataCollatorForLanguageModeling
# 5. Configurar los argumentos de entrenamiento
training_args = TrainingArguments(
output_dir="./lora_fine_tuned_model", # Directorio para guardar el modelo
num_train_epochs=3, # Número de épocas de entrenamiento
per_device_train_batch_size=4, # Tamaño del lote por dispositivo
gradient_accumulation_steps=4, # Pasos de acumulación de gradiente
optim="paged_adamw_8bit", # Optimizador optimizado para memoria
save_steps=100, # Guardar checkpoint cada 100 pasos
logging_steps=50, # Registrar logs cada 50 pasos
learning_rate=2e-4, # Tasa de aprendizaje (común para LoRA)
weight_decay=0.001, # Decaimiento de peso
fp16=False, # Usar bfloat16 si está disponible, si no, fp16=True
bf16=True, # Habilitar bfloat16 si la GPU lo soporta
max_grad_norm=0.3, # Recorte de gradiente
max_steps=-1, # Número máximo de pasos de entrenamiento (-1 para entrenar por épocas)
warmup_ratio=0.03, # Ratio de calentamiento del learning rate
group_by_length=True, # Agrupar secuencias similares para eficiencia
lr_scheduler_type="cosine", # Programador de tasa de aprendizaje
report_to="tensorboard", # Integración con TensorBoard
evaluation_strategy="steps", # Evaluar en cada `eval_steps`
eval_steps=100, # Pasos para la evaluación
load_best_model_at_end=True, # Cargar el mejor modelo al final
metric_for_best_model="eval_loss", # Métrica para determinar el mejor modelo
greater_is_better=False, # Menor pérdida es mejor
)
# 6. Inicializar el Data Collator
# Esto se encarga de preparar los lotes de datos para el entrenamiento,
# incluyendo el enmascaramiento de los tokens de padding.
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
# 7. Inicializar el Trainer y comenzar el entrenamiento
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
data_collator=data_collator,
)
# Desactivar el caché para el entrenamiento
model.config.use_cache = False
# Entrenar el modelo
print("\nIniciando el fine-tuning con LoRA...")
trainer.train()
# 8. Guardar los adaptadores LoRA
trainer.save_model("lora_fine_tuned_model_final")
print("Fine-tuning completado y adaptadores LoRA guardados.")
# Para cargar los adaptadores y fusionarlos con el modelo base (para inferencia)
# from peft import PeftModel
# model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto")
# model = PeftModel.from_pretrained(model, "lora_fine_tuned_model_final")
# model = model.merge_and_unload() # Fusionar los adaptadores con el modelo base
# model.save_pretrained("merged_fine_tuned_model") # Guardar el modelo fusionado
Paso 4
Inferencias y Evaluación Post-Entrenamiento
Una vez entrenado, puedes cargar los adaptadores LoRA y probar el modelo en nuevas entradas para ver cómo ha mejorado su rendimiento en la tarea específica.
6. Casos de Uso Avanzados y Consideraciones Éticas
El fine-tuning de LLMs con LoRA abre un abanico de posibilidades en 2026, permitiendo la personalización de modelos para una infinidad de aplicaciones, desde la mejora de asistentes virtuales hasta la generación de contenido altamente especializado. Sin embargo, también es crucial considerar las implicaciones éticas.
Casos de Uso Avanzados
1. Generación de Contenido para Marketing
Fine-tuning un LLM con datos de marca, tono de voz y guías de estilo para generar automáticamente copias de marketing, publicaciones en redes sociales y descripciones de productos que resuenen con la audiencia objetivo. Se ha observado un aumento del 30% en la tasa de conversión en campañas piloto en 2026.
2. Soporte al Cliente Automatizado
Adaptar un LLM con bases de conocimiento específicas de la empresa y transcripciones de interacciones de soporte para crear chatbots que resuelvan el 85% de las consultas comunes sin intervención humana, reduciendo los tiempos de respuesta en un 60%.
3. Asistencia en Programación y Generación de Código
Fine-tuning con repositorios de código internos y documentación para generar código en estilos específicos de la empresa, depurar errores y escribir pruebas unitarias, aumentando la productividad de los desarrolladores en un 20-25%.
4. Análisis de Documentos Legales y Financieros
Entrenar LLMs con conjuntos de datos de contratos, informes financieros y regulaciones para automatizar la extracción de información clave, resumir documentos y detectar anomalías, mejorando la eficiencia y reduciendo errores en un 40% en comparación con el análisis manual.
Consideraciones Éticas en 2026
Aunque el fine-tuning ofrece un gran poder, conlleva responsabilidades éticas:
- Sesgos en los datos de entrenamiento: El fine-tuning con datos sesgados puede amplificar estos sesgos, llevando a resultados injustos o discriminatorios. Es crucial curar los conjuntos de datos con diligencia.
- Uso indebido: Los modelos finamente ajustados pueden ser utilizados para generar desinformación, spam o contenido ofensivo de manera más convincente.
- Privacidad de datos: Asegúrate de que los datos utilizados para el fine-tuning respeten la privacidad y las regulaciones (como GDPR o CCPA).
- Transparencia y explicabilidad: Es fundamental ser transparente sobre cómo se entrenan y utilizan los LLMs, especialmente en aplicaciones críticas.
ADVERTENCIA
El fine-tuning de LLMs, aunque potente, puede amplificar los sesgos presentes en los datos de entrenamiento. Es imperativo realizar una auditoría exhaustiva de los datos y monitorear el comportamiento del modelo para mitigar riesgos éticos y garantizar un uso responsable de la IA.

7. Desafíos Comunes y Estrategias de Solución
Aunque LoRA simplifica el fine-tuning, aún existen desafíos que los desarrolladores deben abordar para lograr resultados óptimos. En 2026, la experiencia ha enseñado valiosas lecciones sobre cómo superar estos obstáculos.
Desafíos y Soluciones
PROBLEMA 01
Sobreajuste (Overfitting) con Pequeños Datasets
Incluso con LoRA, si el conjunto de datos de fine-tuning es muy pequeño o de baja calidad, el modelo puede sobreajustarse y perder su capacidad de generalización.
SOLUCIÓN
Utiliza técnicas de aumento de datos (data augmentation) para expandir tu dataset. Implementa un early stopping basado en la pérdida de validación. Ajusta los hiperparámetros de LoRA (r y lora_alpha) para reducir la capacidad del adaptador y el lora_dropout.
PROBLEMA 02
Selección Inadecuada de Hiperparámetros LoRA
Elegir los valores correctos para r (rango), lora_alpha (escalado) y target_modules puede ser complicado y afectar el rendimiento.
SOLUCIÓN
Comienza con valores comunes (r=8 o r=16, lora_alpha=r*2). Experimenta con diferentes target_modules, incluyendo las capas de atención y las capas feed-forward. Utiliza herramientas de optimización de hiperparámetros como Optuna o Ray Tune.
Lista de verificación para un Fine-tuning Exitoso
☑ Preprocesamiento de datos de alta calidad y formateo correcto.
☑ Selección adecuada del modelo base para la tarea.
☑ Configuración de BitsAndBytesConfig para cuantificación de 4 bits.
☑ Ajuste de LoraConfig (r, lora_alpha, target_modules).
☑ Monitoreo de la pérdida de entrenamiento y validación.
☑ Evaluación objetiva del modelo finamente ajustado.
☑ Consideraciones éticas y mitigación de sesgos.
8. Evaluación del Rendimiento Post-Fine-tuning
Una vez que el fine-tuning ha concluido, es fundamental evaluar el rendimiento del modelo para determinar si ha aprendido la tarea deseada y si ha superado al modelo base. La evaluación debe ser objetiva y utilizar métricas relevantes para la tarea.
Métricas Clave de Evaluación en 2026
- Perplexity: Una métrica común para modelos de lenguaje que mide qué tan bien predice el modelo una secuencia. Una menor perplexidad indica un mejor ajuste.
- BLEU/ROUGE: Para tareas de generación de texto como resumen o traducción, estas métricas comparan la superposición de n-gramas entre el texto generado y las referencias humanas.
- F1-score/Accuracy: Para tareas de clasificación o extracción de información, son métricas estándar para evaluar la precisión y el recuerdo.
- Evaluación Humana: A menudo, la métrica más importante, especialmente para la calidad subjetiva del texto. Involucra a evaluadores humanos que califican la coherencia, relevancia y fluidez del texto generado.
Es recomendable utilizar un conjunto de datos de prueba independiente que no se haya visto durante el entrenamiento o la validación para obtener una evaluación imparcial del rendimiento del modelo.
9.1
/ 10
Rendimiento promedio de LLMs con LoRA en tareas específicas, según informes de la industria en 2026.
9. Conclusión y el Futuro del Fine-tuning de LLMs
El fine-tuning de Modelos de Lenguaje Grandes (LLMs) con Hugging Face y LoRA representa una de las herramientas más poderosas y accesibles para los desarrolladores de IA en 2026. Esta combinación no solo democratiza el acceso a la personalización de modelos de vanguardia, sino que también establece un nuevo estándar de eficiencia en el entrenamiento de IA.
Hemos visto cómo LoRA supera las limitaciones del fine-tuning tradicional al reducir drásticamente los requisitos de memoria y computación, permitiendo que organizaciones de todos los tamaños adapten LLMs a sus necesidades específicas. Hugging Face, con su robusto ecosistema de librerías y un Hub colaborativo, proporciona la infraestructura esencial para que estos avances sean posibles y escalables.
Mirando hacia el futuro, se espera que las técnicas PEFT como LoRA sigan evolucionando, con investigaciones enfocadas en mejorar aún más la eficiencia, la capacidad de generalización y la robustez. La integración de LoRA con técnicas de Reinforcement Learning from Human Feedback (RLHF) y la optimización para hardware especializado (como los aceleradores de IA de nueva generación) serán áreas clave de desarrollo en los próximos años. El fine-tuning eficiente no es solo una tendencia; es una parte integral del ciclo de vida de los LLMs, asegurando que estos modelos puedan seguir adaptándose y ofreciendo valor en un mundo en constante cambio.
Ventajas del Fine-tuning LoRA
✓ Reduce drásticamente los requisitos de VRAM y tiempo de entrenamiento.
✓ Permite el fine-tuning de LLMs grandes en hardware accesible.
✓ Facilita la creación y gestión de múltiples adaptaciones de modelos.
✓ Mantiene un rendimiento comparable al fine-tuning completo en muchas tareas.
Desafíos a Considerar
✗ Requiere un buen conjunto de datos específico para la tarea.
✗ La selección de hiperparámetros LoRA aún requiere experimentación.
✗ Riesgo de sobreajuste si los datos de entrenamiento son escasos o de baja calidad.
Preguntas Frecuentes sobre Fine-tuning de LLMs con LoRA
Q. ¿Qué es LoRA y por qué es tan relevante en 2026 para los LLMs?
LoRA (Low-Rank Adaptation) es una técnica de fine-tuning eficiente que entrena un pequeño conjunto de parámetros adicionales en lugar de todas las capas de un LLM. Es relevante en 2026 porque permite adaptar modelos gigantescos a tareas específicas con significativamente menos recursos computacionales y memoria, democratizando el acceso a la personalización de IA.
Q. ¿Necesito una GPU de alta gama para hacer fine-tuning con LoRA?
No necesariamente. Gracias a LoRA y la cuantificación de 4 bits (BitsAndBytes), es posible realizar fine-tuning de modelos de 7B o 13B en GPUs de consumo con 24GB de VRAM, como una NVIDIA RTX 3090 o 4090. Esto contrasta con el fine-tuning tradicional que requeriría múltiples GPUs de servidor.
Q. ¿Es el rendimiento de un LLM ajustado con LoRA comparable al de un fine-tuning completo?
En una amplia gama de tareas y dominios, el rendimiento de un LLM ajustado con LoRA es sorprendentemente comparable al de un fine-tuning completo. La clave reside en que los cambios necesarios para adaptar un modelo a una nueva tarea a menudo tienen una estructura de bajo rango, que LoRA captura de manera efectiva.